-
OmniBench: Towards The Future ofUniversal Omni-Language Models공부/논문 2026. 1. 6. 16:01728x90
https://arxiv.org/abs/2409.15272
OmniBench: Towards The Future of Universal Omni-Language Models
Recent advancements in multimodal large language models (MLLMs) have aimed to integrate and interpret data across diverse modalities. However, the capacity of these models to concurrently process and reason about multiple modalities remains underexplored,
arxiv.org
Abstract
MLLM(Multimodal Large Language Model)의 발전은 지속되어 왔으나, 이에 대한 벤치마크는 아직 부족한 상태
그래서 vision, acoustic, textual input으로 받는 모델(OLM, Omni Language model)의 능력을 평가하는 benchmark 설계
84.5K개의 dataset 완성(OmniInstruct) 링크 : https://m-a-p.ai/OmniBench/
OmniBench
🔥[2024-09-22]: We release the new benchmark for text, image, and audio large language models! Recent advancements in multimodal large language models (MLLMs) have aimed to integrate and interpret data across diverse modalities. However, the capacity of
m-a-p.ai
1. Introduction
멀티모달이 계속해서 발전하고 있지만, 3가지 input을 동시에 처리하는 영역은 아직임
멀티모달을 발전시키려면 개발뿐만 아니라 성능을 평가하는 것도 함께 발전해야함
다만, 현재 벤치마크들은 1가지 input에만 초점을 맞추거나, VLM, ALM 등에만 국한되어 있음
Omnibench를 모든 멀티모달 맥락에 대해 이해하고, 이를 이용해 통합된 이해와 추론을 요구하는 제약 조건을 부과함
인간의 인지에 좀 더 가까워진 평가
Omnibench를 통해 측정한 MLLM들의 한계
- opensource 모델들 대부분 random guess accuracy는 넘어서지만 특정 경우에 능력을 내지 못 하는 경우가 있음
- proprietary 모델들은 대부분 나은 성능을 보이지만 image/audio 하나를 제거하면 opensource보다 더 많은 accuracy 하락을 보임
- 모델보다 인간이 낫다
- 3개의 양식을 모두 사용하며 맥락을 이해하는 능력은 아직 부족해보임
2. Related Work
Multimodal Large Language Models
OLM의 정의 : 적어도 3개이상의 서로 다른 모달리티를 동시에 입력받아 이해, 추론할 수 있는 언어 모델
Multimodal Understanding Benchmark
image, audio, text를 동시에 요구하는 벤치마크가 적음
Audio-Visual Understanding Datasets
추론에 대한 평가가 부족한 경우가 다수
일부 데이터셋은 단일 모달에서도 response를 추론할 수 있기 때문에 진정한 멀티모달이 아님
3. OmniBench
image, audio, text 3개의 input을 지원하는 MLLM을 평가하기 위한 벤치마크 제안
3.1. Benchmark Design
3 primary categories

1. (temporal)-spatial entity
- Object Identification
- Contextual&Environmental
2. causal inference
- Story Cause Description
- Current Action&Activity
- Future Plot and Purpose Inference
3. abstract concept
- Identity&Relationship
- Text&Symbols
- Count&Quantity
1142개의 QA쌍
3.2. Annotation Protocol
Annotation Scheme
각 질문에 대한 정답은 image, audio 모두가 필요해야함
기준에 못 미치면 수정 작업을 거쳤음
Q는 MCQ 형태
480p이상, 최대 30s의 오디오
원천 데이터를 최대 5회 사용하도록 제한
Quality Control
human inspection과 automatic inspection으로 이루어짐
QA쌍은 human inspection을 먼저 거치고, LLaVA1.6 34B로 automatic inspection을 거침
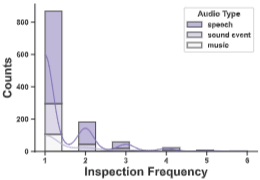
통과된 샘플의 분포 3.3. OmniInstruct
tri-modal reasoning 능력을 향상시키기 위해 모델의 supervised fine-tuning을 용이하게 하는 96k의 데이터셋 개발
4. Experiment Settings
Baseline Systems
1. omni-language models
MIO-Instruct, AnyGPT, VideoSALMONN, UnifiedlO2, VITA, OpenOmni, Baichuan-Omni-1.5, Qwen-2.5-Omni
2. vision-language models
InternVL-2, Qwen2-VL, Deepseek-VL, LLaVA-One-Vision, Cambrian, Xcomposer2-4KHD, Idefics2, Mantis-Idefics2
3. audio-language models
LTU, Mu-LLaMA, MusiLingo, Qwen-Audio, SALMONN-Audio, Audio-Flamingo
Omni-Understanding Evaluation
OmniBench의 주요 초점은 image, audio, text 정보가 주어진 상황에서 얼마나 잘 이해하고 재구성할 수 있는 지를 평가하는 것
모델에게 4가지 선택지를 가진 Q를 전달하고 정답을 선택해서 얼마나 일치하는 지(accuracy)를 평가 지표로 사용(random guess model은 25%의 accuracy를 보였다고 함)
Textual Approximation of Image and Audio
2개의 모달만 지원하는 모델에 대해서는 대안을 보충해줘서 잠재력 테스트
VLM은 audio 전사본을 오디오 대안으로 사용
ALM은 이미지에 대한 상세한 캡션을 대안으로 사용
5. Findings
5.1. Results on Omni-Language Models
Overall
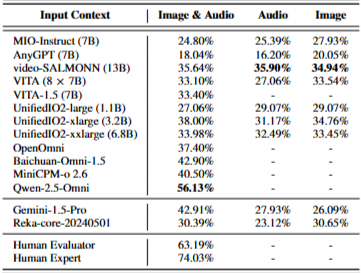
전반적으로 대부분의 오픈소스는 random guess accuracy를 능가함
Breakdown Results

오디오 유형마다 다르게 결과가 나옴
오픈소스 모델들은 일반적으로 음성 오디오에서 더 높은 정확도를, Video-Salmonn이랑 Gemini-1.5-Pro는 음악 오디오에서 더 높은 정확도를 보임
대체적으로 Object Identification&Description에서 잘함
Plot Inference나 Story Description과 같은 복잡한 추론 작업에서는 성능이 떨어짐
Count&Quantity에서 Gemini-1.5-Pro, Reka-core-20240501, Video-SALMONN같은 건 상당히 낮은 성능을 보이고 UnifiedIO모델은 잘함
Results on Music-related Questions
음성에 비해 음악은 저작권으로 인해서 더 비싸고 제한적
Human Evaluation
3명이서 human evaluation해서 63.19%의 accuracy, 0.421의 Fleiss' Kappa값을 가짐
모델과 달리 인간은 Sound Event(아마도 효과음?같은 거), Abstract Concept에서 더 높은 점수를 보여줌
5.2. The Effectiveness of OmniInstruct
6.4K sample(전체 데이터셋의 약 7.5%)사용하여 MIO-instruct-OmniV1 7B로 fine-tuning했더니 유의미하게 개선이 되었음
Baseline 24.8% accuracy=>fine-tuning이후 25.7%로 향상
전체 데이터셋으로 MiniCPM-o-2.6을 학습시키면 Baseline 40.5% accuracy=>fine-tuning이후 45.9%로 향상
5.3. Textual Approximation on Images and Audios

'공부 > 논문' 카테고리의 다른 글
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (7) 2025.08.07 Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey (1) 2025.06.09 MT-Bench-101: A Fine-Grained Benchmark for Evaluating LargeLanguage Models in Multi-Turn Dialogues (2) 2025.03.01 Unifying Short and Long-Term Tracking with Graph Hierarchies (0) 2024.08.10 Segment Anything (0) 2024.08.03