-
MT-Bench-101: A Fine-Grained Benchmark for Evaluating LargeLanguage Models in Multi-Turn Dialogues공부/논문 2025. 3. 1. 16:31728x90
https://arxiv.org/pdf/2402.14762
Abstract
LLM을 평가하는 것은 여전히 도전 과제
이전의 벤치마크들은 single turn위주이거나 multi turn이어도 불완전한 평가를 제공하여, complexity나 세부적인 부분을 놓쳤음
그래서 multi-turn을 제대로 평가하기 위해 만들어진 게 MT-Bench-101!
13개의 task로 1388개의 세션에서 4208 turn을 포함하는 3단계 계층적 평가 체계를 구축
21개의 LLM으로 실험 진행
1. Introduction
LLM은 엄청난 발전을 해옴
그에 따라 여러 평가 기준도 도입(ex. MMLU, BBH, AlpacaEval 등)
하지만 실제 대화에서는 보통 multi-turn 대화가 주를 이룸
그래서 LLM이 대화를 하면서 일관된 response를 generation하는 것을 평가하는 것이 필수!
MT-bench같은 초기 연구들은 주로 2-turn에 집중하고 있고 평가지표가 세부적인 부분까진 보지 못함

Perceptivity
가장 기본적인 능력, 모델이 맥락을 이해하는 능력
Context Memory, Understanding, Anaphora, Topic Shift
Adaptability
사용자 피드백에 잘 대응하는가
Content/Format Rephrasing, Multi-turn Reasoning
Interactivity
능동적인 교감
Questioning, Clarification, Proative interaction
MT-Bench-101은 multi-turn을 3가지 주요 ability와 13개의 task로 나누어 세분화된 벤치마크 제공

MT-Bench-101의 평가지표 분류 체계 평가에는 GPT-4를 사용
각 작업에 대한 고유 평가 가이드라인을 설계
총 점수는 가장 낮은 round의 점수를 사용하여 합리적인 평가
- LLM이 주로 부족한 능력은 adaptability와 interactivity
- GPT가 가장 점수가 좋았음
- 다양한 task에서 모델의 성능은 turn마다 달라짐
- 모델 성능은 모델 크기에 비례해서 증가하는 것이 일반적이나, multi-turn은 딱히 그래보이지 않았음
2. Related Work
LLMs for Multi-turn Dialogues
Vicuna, RealChat, Baize, UltraChat, Parror, Cue-CoT, In-Context-Learning(ICL), ICL-AIF
Benchmarks for Multi-turn LLMs
대부분의 LLM 평가 지표는 single-turn이고, 뉘앙스같은 걸 캐치 못 함
ABC-Eval, AlpacaEval, PandaLM, MT-Bench, MT-Bench++, BotChat, MINT
Benchmarks for Fine-grained Abilities
포괄적이고 다양한 평가의 필요성
MMLU, ConceptMath, Follow-Bench
3. MT-Bench-101
3.1. Hierarchical Ability Taxonomy
인간과 LLM의 대화를 효과적으로 평가하기 위해 LLM의 능력을 계층적으로 분류하여 체계를 만들었음
3.1.1. Perceptivity
LLM이 과거의 대화를 활용하여 논리적이고 일관된 response를 generate하는가?
1. Context Memory(CM)
과거 대화의 세부 사항을 기억하고 현재 user의 질문에 대응하기 위해 이를 회상하는 능력
2. Context Understanding(CU)
- Anaphora Resolution(AR) : user가 사용하는 대명사(ex. 이거, 저거)의 참조 대상을 정확히 식별하여 응답을 생성하는가?
- Separate Input(SI) : 여러 턴에 걸쳐 대화가 진행될 때, 첫번째 턴에서 제시된 요구사항과 이후 턴에서 입력들과의 관계를 이해하는가?
3. Context Inference(CI)
- Topic Shift(TS) : user가 주제를 갑자기 변경했을 때, 이전 정보는 무시하면서 새로운 주제에 집중하는가?
- Content Confusion(CC) : user가 비슷한 질의들을 해도 맥락상으로 잘 이해하고 응답을 하는가? ex)user가 반복해서 "영화 추천 좀"하면 이전에 추천했던 건 추천 안 한다든가 하는 거
3.1.2. Adaptability
LLM이 user의 요구에 따라 초기 response를 조정하는 능력
1. Content Rephrasing(CR)
user의 최신 요구 사항에 따라 마지막 response를 rephrase하는 능력
2. Format Rephrasing(FR)
원래 정보를 유지하면서 format만 변환 ex)이 문서를 list 형식으로 변환해주세요
3. Reflection
user의 피드백을 받아들여 response를 repharsing
- Self-correction(SC) : user의 비판, 오류 지적에 따라 답변 수정
- Self-affirmation(SA) : user가 이전 응답에 대해 잘못된 피드백을 줬을 때에도 LLM은 올바른 답변을 하는가?
4. Reasoning
새로운 조건, 가정을 수용하는가?
- Mathematical Reasoning(MR) : 복잡한 수학 문제를 user와 협력하여 해결할 수 있는 능력
- General Reasoning(GR) : 퍼즐, 귀납적 및 연역적 추론 문제를 해결하는 능력
3.1.3. Interactivity
더 나은 response를 위해 적극적으로 질문함
1. Questioning
- Instruction Clarification(IC) : 사용자의 초기 질문이 불명확할 때, 더 많은 정보를 얻기 위해 후속 질문을 함, LLM이 사용자의 의도를 완전히 파악할 때까지 여러 차례 이어질 수 있음
- Proactive Interaction(PI) : user의 의도에 반응하여 후속 질문이나 coment를 하는 능력을 평가, 대화가 지속적, 연속적인 느낌을 들 게 함
Task Abbr Description Context Memory CM user q에 대한 response를 위해 이전 대화들을 recall Anaphora Resolution AR 대명사(ex.이것, 저것)의 대상을 식별 Separate Input SI 첫번째 turn의 task 요구사항과 후속 turn들의 관계를 이해 Topic Shift TS user가 예기치 않게 topic을 바꿀 때, 새 주제에 집중 Content Confusion CC 대화에서 다른 의미의 비슷한 질의로부터 혼란을 피하는 지 Content Rephrasing CR user의 최신 요구 사항에 따라 마지막 response의 내용을 rephrase Format Rephrasing FR user의 최신 요구 사항에 따라 마지막 response의 형식을 rephrase Self-correction SC user의 피드백에 따라 response 수정 Self-arrirmation SA 부정확한 user 피드백이 와도 올바른 response 출력 Methematical Reasoning MR multi turn 속에서 user와 복잡한 수학 문제를 함께 해결 General Reasoning GR multi turn에서 user와 복잡한 추론 문제 함께 해결 Instruction Clarification IC 모호한 user의 q에 대해 추가 질문으로 명확화 Proactive Interaction PI user의 의도에 반응하여 대화 지속을 위한 적절한 response 출력 - Hierarchical Ability Taxonomy 정리
3.2. Data Collection
각 작업의 특성을 기반으로 prompt를 조정하여 gpt4를 활용해서 데이터셋을 만들었음
prompt는 데이터 생성 format을, 수작업으로 만든 예제를 fewshot으로 제공
30개의 다양한 주제(ex.건강, 역사, 과학, 금융 등)
human eval을 통해 최종 데이터셋을 형성
3.3. Data Statistics

task는 13개(위에 적은 hierarchical ability taxonomy)
1338개의 session(dialogue)와 4208개의 turn
fine-grained에 초점
3.4. Evaluation
선별한 데이터셋을 golden set으로 사용
GPT-4를 평가에 사용
평가 프롬프트를 작성하여 점수를 1~10점 중 하나로 매기고 설명을 적도록 했으
평가는 session(dialogue)에서 turn단위로 점수를 뽑아 그 중 가장 낮은 점수를 최종 점수로 간주
why? 단 한 번의 실수가 전체 대화를 손상시킬 수도 있기 때문
(ㄷㄷ....99번을 성공해도 1번을 실수하면,,,)근데 데이터셋이 GPT4로 생성됐기 때문에(LLM judge은 self-bias가 있다 ex.GPT는 GPT가 만든 답변을 더 좋아함) 다른 모델(Qwen-72B)로도 평가해봤고 일관적인 결과가 나오는 것을 확인했음
4. Experiments
4.1. Experimental Setup
Settings
temperature는 0.6으로 설정
Models
21개의 LLM으로 평가 진행
4.2. Main Results

각 task 별 LLM들의 능력 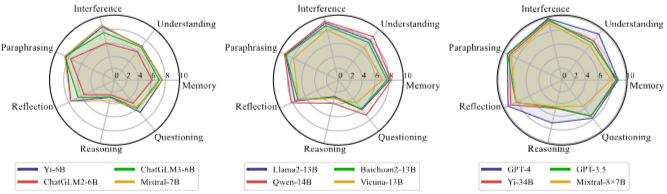
각 ability dimension마다의 다양한 llm들의 능력 Task Dimensional Analysis
모든 task중에서 CC(content Confusion), FR(Format-Rephrasing)은 덜 어려워 하는 반면, MR(Mathematical Reasoning)은 어려워 하는 걸로 결과가 나옴
closed-source model들이 open-source model들보다 우수한 성능을 보임
GPT-4가 1등, Yi-34B가 2등
Ability Dimensional Analysis
1. 대부분의 LLM은 rephrasing과 confusion에는 강한 것을 알 수 있으나, reasoning이나 questioning에는 아직 약한 모습
2. memory 능력은 understanding 능력을 초과
memory 능력은 주로 정보를 recall하는 것과 관련이 있는 반면, understanding은 의미를 파악하는 것이기 때문에 더 깊은 수준의 cognitive processing이 필요하기 때문
3. reflection과 questioning 능력은 multi-turn에서 user와 interacitvity에 중요한 역할, 대화의 일관성을 유지하는 데 필수
그리고 reflection, questioning 능력이 뛰어난 모델은 각 task에서도 능숙한 것 뿐만 아니라, 전체적인 conversational 지능이 더 높음을 나타냄
Chat-Specific Models
채팅 전용 LLM인 Baize와 UltraLM이 뛰어난 성능을 보이진 않음
즉, 채팅 특정 모델이라해도 multi-turn 시나리오를 위해서는 추가적으로 개발이 되어야 함을 나타냄
Per-Turn Performance

모델 성능에 대한 turn 수의 영향을 조사하기 위해 턴 수에 따른 평균 점수를 계산
a,b에서 보이는 바와 같이 pharaprasing, context memory, anaphora resolution task, topic shift, confusion 에서 모델의 평균 성능은 첫번째 turn과 후속 turn들의 사이에서 감소하는 경향=>multi-turn에서 모델들이 이전 턴의 내용을 잊거나, 대화가 진행됨에 따라 bias를 나타내는 경향이 있음을 시사
c에서 보이는 바와 같이 separate input, directive clarification, proactive interaction은 turn수가 증가함에 따라 성능이 상승하는 경향
d에서 보이는 바와 같이 mathmatical reasoning에서는 특정 패러다임(ex. step-by-step)을 사용하여 오히려 점수가 높아짐, 근데 general reasoning같이 고정된 패러다임이 없는 task에서는 오히려 떨어지는 걸 볼 수 있음
4.3. Further Analysis
Effect of Model Size

역시나 모델 크기가 크면 똑똑한 걸 알 수 있었음
특히, 모델 크기가 커지면 questioning ability에 중요한 영향을 줬음
즉, 모델이 크면 향상된 interactivity 능력을 보여준다는 것
Effect of Human Preference Alignment
RLHF/DPO, SFT 비교

생각보다 RLHF/DPO는 크게 증가하는 게 안 보였고, 심지어 mistral은 감소했음=>RLHF/DPO는 multi-turn에서는 그닥 성능 개선에 큰 도움이 되지 않는다는 걸 보여줌
Effect of the Golden Context
golden context가 model이 맥락 내 학습을 위한 데이터를 제공하여 특정 패턴, 스타일을 학습함으로써 점수가 상승
반대로 self-predicted context를 대화 이력으로 사용하면 잘못된 응답으로부터 오류가 누적되어 점수가 하락
4.4. Case Study
세부 사항을 받기 전에 미리 답변을 생성하는 문제
초기 요구 사항을 잊어버려서 원래 과제에서 벗어난 답변을 하는 문제가 있었음
4.5. Human Evaluation

MT-Bench-101에서 100개를 random sampling하여 5명의 전문가가 LLM의 multi-turn이 해당 task를 충족하는 능력을 보여줬는 지 평가
GPT-4와 human eval의 alignment는 87%였음
human끼리의 alignment는 80%였음ㄷㄷ
근데 점수 기준이나, 평균 값을 사용하지 않을 경우에는 alignment가 감소하는 경향이 있었음
5. Conclusion
multi-turn에서 LLM의 능력을 평가하기 위한 MT-Bench-101 벤치마크 소개
기존 평가 방법들은 single-turn에 주로 초점을 맞췄었음
MT-Bench-101을 통해 평가한 결과, RLHF, DPO같은 방법들은 multi-turn의 능력을 개선하는 데 효과적이지 않음 을 알 수 있었음
+데이터 생성에 사용한 프롬프트 및 평가에 사용한 프롬프트, case study는 appendix에 실려있으니, 고거슬 참고
고것까지 다 들고와서 보기엔 체력, 시간 이슈로 리뷰는 여기서 끝!
'공부 > 논문' 카테고리의 다른 글
Unifying Short and Long-Term Tracking with Graph Hierarchies (0) 2024.08.10 Segment Anything (0) 2024.08.03 An Image is worth 16*16 words: Transformers for image recognition at scale (0) 2024.06.06 StyleGAN 1~3 논문 리뷰 (1) 2024.03.19 Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models(Nightshade) (1) 2024.02.22