-
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS공부/논문 2025. 8. 7. 16:10728x90
https://arxiv.org/pdf/2106.09685
Abstract
full-finetuning은 빡세다
그래서 pretrained model weights는 freeze시키고 각 레이어에 rank decomposition matric을 추가해서 파라미터 수를 줄이는 LoRA를 제안!
GPT-3 175B랑 비교했을 때 파라미터 수는 10000배 줄이고 gpu는 3배 줄일 수 있음
그런데도 모델 성능은 비슷하거나 더 나아짐
1. Introduction
nlp는 대부분 pretrained model을 finetuning하는 식으로 진행
근데 동일한 수의 파라미터를 학습하는 게 에바
그래서 일부 파라미터만 조정하거나 외부 모듈을 학습시켜서 완화하려고 했었음
근데 이럴 경우 inference latency가 발생하거나, sequence length를 줄이는 등의 문제가 발생
해당 논문의 저자들은 파라미터가 왕많은 모델들이라도 실제로 학습 과정에서 의미있는 변화가 일어나는 공간은 생각보다 훨씬 적은 차원을 가지지 않을까?에서 시작
그래서 나온 게 Low-Rank Adaptation(LoRA)
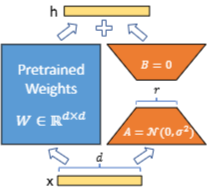
LoRA의 이점
1. storage requirement와 task-switching overhead를 크게 줄일 수 있음
2. 학습 효율성을 높이고 하드웨어 진입 장벽을 낮춰줌
3. inference latency 발생하지 않음
4. 다양한 방법들과 결합해서 사용 가능
2. Problem Statement
아래는 기존에 pretrained autoregressive language model을 finetuning하기 위한 objective function

Φ : pretrained model의 전체 파라미터
Z : 훈련 데이터셋
x : context
y : target
=>x(context)와 t(지금)전까지 생성된 y(target tokens)가 주어졌을 때, yt(지금 target token)이 나타날 확률(P Φ)에 대한 로그값(1. log부분)을 시퀀스 내의 모든 토큰에 대한 예측 확률을 고려(2.시그마 t=1, |y| 부분)하고 Z(훈련 데이터셋)에 있는 모든 x,y(context-target 쌍)에 대해 합산(3. 시그마 (x,y) ∈ Z 부분)하여 Φ(모델 파라미터)를 최적화하여 목적 함수의 값을 최대화(4. max Φ 부분)
pretrained model이 finetuning할 때 모델이 생성하는 각 토큰의 로그 확률을 최대화하여 모델의 모든 파라미터를 조정
얘는 LoRA 적용 objective function

대부분은 동일하니 log안에 P_(Φ0+ ∆Φ(θ)) 부분만 보자
Φ0 : pretrained model의 기존 가중치
Φ(θ) : low rank matrix를 구성하는 파라미터
∆Φ(θ) : low rank 파라미터 변화량
=> pretrained model weight에 아주 적은 수의 추가 파라미터(Φ(θ))를 추가하여 fine-tuning
3. Aren't existing solutions good enough?
기존 fine-tuning 학습을 최적화하려는 전략
1. 어댑터 레이어 추가
2. input layer activations의 일부를 최적화
하지만 둘 다 inference latency 문제가 있었음
4. Our method
4.1. Low-Rank-Parametrized update matrices
특정 task에 대해 fine-tuning 할 때 낮은 차원의 고유 랭크(instrinsic rank)를 가진다고 가정하면 아래와 같은 forward pass를 가진다고 할 수 있음
h = W0x + ∆Wx = W0x + BAx
(x : input vector, h : output vector)
∆Wx는 BAx로 즉, 더 작은 행렬 두 개의 곱으로 분해됨
=>그렇다면 B와 A는 어케 구함?
A는 임의의 가우시안 분포로 초기화, B는 0으로 초기화
그래서 학습 초기에는 ∆W = 0
∆W는 이후 α/r 상수로 스케일링됨, α는 상수이고 보통 r과 동일하게 설정됨
얘는 왜 쓰는 거냐면 α를 튜닝하는 게 learning rate를 튜닝하는 것과 거의 같은 효과를 낸다고 함
A Generalization of Full Fine-tuning
r의 최대치 = min(d,k)임에도 d*k의 파라미터의 표현력을 거의 가지게 됨
더보기엥 근데 d=k=100이고 r도 100이라면?LoRA가 손해 아님?
=>마즘, 근데 r은 대부분 4, 8, 16 과 같은 매우 작은 수로 정해지므로 이럴 일이 거의 없다고 함
No Additional Inference Latency
가중치는 합쳐져서 사용되므로(W0+BA) 지연되지 않음
task를 바꾸고 싶을 때는 BA행렬만 바꿔주면 돼서 task-switching overhead도 낮음
4.2. Applying LoRA to Transformer
self-attention모듈에 4개의 가중치 행렬(wq, wk, wv, wo)에 적용
Practical Benefits and Limitations
장점 : memory, storage 사용량 감소
단점 : LoRA A,B행렬이 기존 가중치와 합쳐지는 경우 태스크 스위칭이 어려움
5. Empirical Experiments
RoBERTa, DeBERTa, GPT-2, 3에서 실험
5.1. Baselines
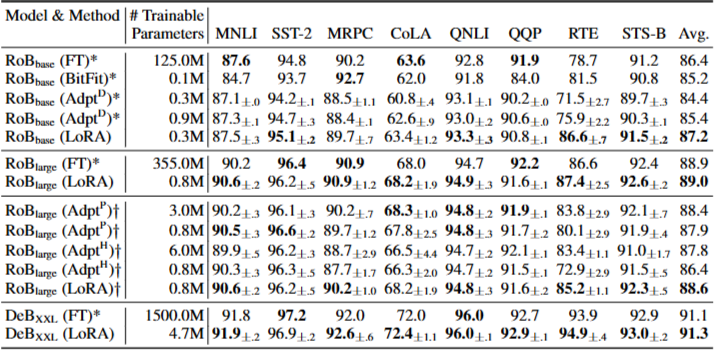


FT : fine tuning
BitFit : bias vector만 학습시키는 방법
Prefix-embedding tuning(PreEmbed) : input token 사이에 special token 삽입
Prefix-layer tuning(PreLayer) : PreEmbed의 확장 버전, 일부 special token에 대해 word embedding을 학습하는 것 대신activation을 학습
Adapter tuning : self-attention과 subsequent residual 사이에 adapter layer 삽입
- AdapterH : Transformer 블록 당 2개의 adapter layer를 가짐
- AdapterL : MLP module 다음 LayerNorm 이후 1개의 adapter layer
- AdapterDrop : 일부 adapter layer를 drop
- LoRA : 기존 가중치+rank decomposition matrics 추가
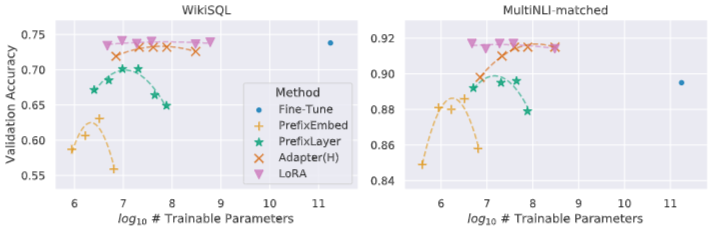
6. Related Works
Transformer Language Models
Prompt Engineering and Fine-tuning
Parameter-Efficient Adaptation
Low-Rank Structures in Deep Learning
7. Understanding the Low-Rank updates
7.1. Which weight matrices in transformer should we apply LoRA to?

transformer에서 어떤 weight matrices에 LoRA를 적용해야 할까? => self-attention 전부 적용해라~
7.2. What is the optimal rank r for LoRA?
r이 모델 성능에 대해 미치는 영향

Subspace similarity between different r

가중치 업데이트에 필요한 핵심 정보는 소수에 쏠려있음
Subspace similarity between different random seeds
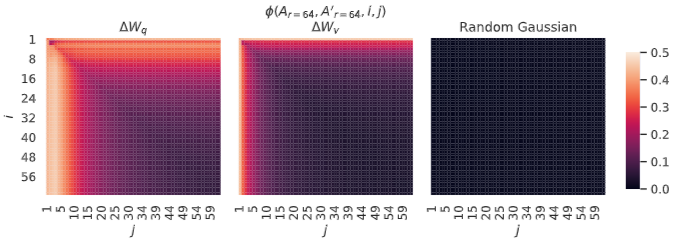
7.3. How does the adaptation matrix ∆W compare to W?

8. Conclusion and Future Work
LoRA는 짱이다
'공부 > 논문' 카테고리의 다른 글
OmniBench: Towards The Future ofUniversal Omni-Language Models (0) 2026.01.06 Attacks, Defenses and Evaluations for LLM Conversation Safety: A Survey (1) 2025.06.09 MT-Bench-101: A Fine-Grained Benchmark for Evaluating LargeLanguage Models in Multi-Turn Dialogues (2) 2025.03.01 Unifying Short and Long-Term Tracking with Graph Hierarchies (0) 2024.08.10 Segment Anything (0) 2024.08.03