-
Segment Anything공부/논문 2024. 8. 3. 20:25728x90
SAM2가 나온 기념으로 SAM 논문 리뷰!
https://arxiv.org/pdf/2304.02643

Abstract
SA 프로젝트 : image segmentation을 위한 새로운 task, model, dataset
1. Introduction
LLM은 zero-shot, few-shot generalization를 통해 NLP에 혁신을 일으키는 중
이러한 foundation model은 일반화 가능
이런 일반화는 프롬프트 엔지니어링을 통해 구현되는 경우가 많음
CV에서는 NLP만큼은 아니지만 연구되어 왔음
ex)CLIP, ALIGN
constrastive learning을 통해 text, image encoder를 훈련
훈련된 encoder는 새로운 시각적 개념, 데이터 분포에 대한 zero-shot generalization 가능
또한 이런 encoder들은 downstream task도 가능(ex. 이미지 생성, DALL-E)
CV에는 풍부한 train dataset이 존재하지 않음
SA프로젝트에서의 목표는 image segmentation을 위한 foundation model 구축
generalization이 가능한 task를 수행할 model을 개발하고, 광범위한 dataset에 대해 훈련, 프롬프트 엔지니어링을 통해 다양한 downstream task를 해결하는 것을 목표
이 프로젝트가 성공하기 위해선 task, model, data 3가지 구성요소에 달려있음
아래 3가지 질문에 대해 해결책을 제시해나가는 구조
1. zero-shot generalization을 가능하게 하는 task는?
2. model architeture는?
3. 어떤 data가 이 task와 model을 완성할 수 있을 것인가?
->해결하기 위해선?
1. 다양한 downstream task를 지원할 수 있을 만큼 일반적인 프롬프팅 가능한 segmentation task를 정의하는 것부터 시작
2. 1을 위해선 flexible한 프롬프트를 지원하고 대화형을 허용하기 위해 프롬프트 시, segmentation mask를 실시간 출력할 수 있는 모델이 필요
3. 2의 모델을 만들기 위해선 대규모 dataset이 필요
Task
segmentation prompt가 주어지면 segmentation mask를 반환하는 것이 목표인 프롬프트 가능 segmentation task 제안
프롬프트는 이미지에서 분할할 대상을 지정
mask는 프롬프트가 모호하고 여러 개체를 나타낼 수 있는 경우에도 그 중 하나에 대한 마스크여야함
Model
프롬프트 가능한 segmentation task와 real world 사용이라는 목표는 모델 아키텍처에 아래와 같은 제약을 걺
1. flexible prompt를 지원
2. 대화형 사용을 위해 실시간으로 마스크를 계산
3. 모호성을 인식해야함
image encoder가 이미지 임베딩을 계산하고 prompt encoder가 프롬프트를 임베딩한 후 두 정보를 lightweight mask decoder에서 결합하면 앞의 3가지 문제가 해결된다는 걸 발견
=>SAM 모델의 탄생
이미지 인코더+빠른 프롬프트 인코더/마스크 디코더로 분리하면 동일한 이미지 임베딩을 다른 프롬프트에 재사용가능
이미지 임베딩이 주어지면 프롬프트 인코더와 마스크 디코더는 50ms이내에 프롬프트에서 마스크 예측
point, box, text 프롬프트로 output출력
Data Engine
새로운 데이터 분포에 대해 generalization을 달성하기 위해서는 이미 존재하는 dataset을 넘어선 dataset에 대해 SAM을 훈련해야함
foundation model을 위한 일반적인 접근 방식은 온라인에서 데이터를 얻는 것이지만 mask는 자연적으로 풍부하지 않음
=>데이터 엔진을 구축하여 해결
model-in-the-loop dataset annotation을 사용
데이터 엔진은 1. assisted-manual 2. semi-automatic 3. fully automatic 의 3단계로 구성
1. assisted-manual
SAM이 사람이 마스크 labeling 지원
2. semi-automatic
SAM이 객체 하위 집합에 대한 마스크를 자동으로 생성, 객체 위치 알려주고 사람은 나머지 객체에 annotation
3. fully automatic
SAM에게 grid제공 하여 이미지당 평균 약 100개의 mask생성하도록
Dataset
최종 데이터 셋인 SA-1B에는 1100만 개의 이미지에서 추출한 10억 개 이상의 mask
data engine의 최종 단계를 사용해 완전 자동으로 수집
2. Segment Anything Task
next token prediction task를 foundation model pretraining에 사용하고 prompt engineering으로 downstream task를 해결하는 NLP에서 영감을 얻었다고 함
Task
프롬프트의 개념을 NLP에서 segmentation으로 변환하는 것부터 시작
여기서 프롬프트는 이미지에서 segmentation할 대상을 나타내는 모든 정보가 될 수 있음
=>promptable segmentation task는 프롬프트가 주어지면 "valid" mask를 반환하는 것(모호한 프롬프트에 대해서 언어 모델은 일관적인 출력을 할 것을 기대하는 것과 유사)
"valid" mask? 프롬프트가 모호하고 여러 개체를 나타낼 수 있는 경우에도 하나 이상의 개체에 대해 합리적인 mask를 출력

Pretraining
promptable segmentation task는 각 훈련 샘플에 대해 일련의 프롬프트(point, box, mask)를 시뮬레이션하고 모델의 mask prediction과 ground truth와 비교하는 pretraining algorithm 제안
사용자 입력 후 최종적으로 valid mask를 예측하는 것이 목표인 interactive segmentation을 응용한 것이지만, SAM에서는 프롬프트가 모호한 경우에도 항상 valid mask를 예측하는 것이 목표(쉽지 않은 task라 특수 모델링 및 training loss 선택이 필요)
Zero-shot transfer
pretraining은 inference 시 어떤 프롬프트에도 적절하게 응답할 수 있는 능력을 모델에 부여
downstram task는 적절한 프롬프트 엔지니어링을 통해 해결 가능
Discussion
prompting과 composition은 single model을 여러 task에 확장하기에 좋은 도구
3. Segment Anything Model
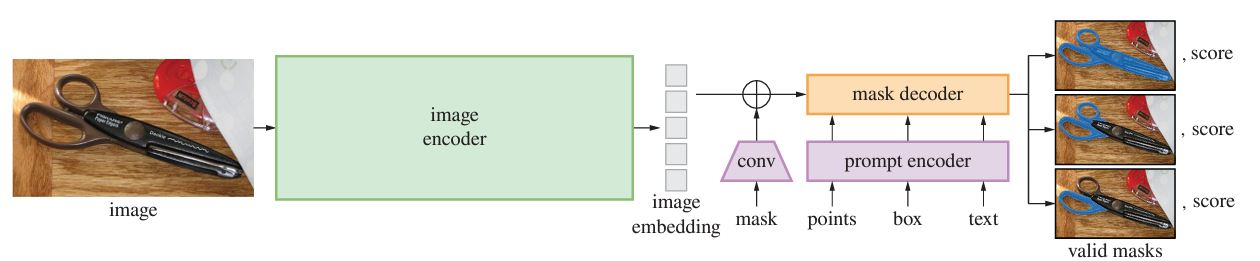
SAM은 image encoder, prompt encoder, mask decoder 3가지로 이루어짐
Image encoder
최소한의 조정만을 거친 MAE pretrained ViT 사용
image encoder는 이미지 당 한 번 실행, 모델에 프롬프트하기 전 적용
Prompt encoder
prompt의 2가지 타입을 고려 : dense(mask)+sparse(point, box, text)
point, box는 각 유형에 따라 학습된 임베딩+position encoding으로 표현
text는 CLIP
mask는 conv를 사용하여 embedding 후, image embedding과 합산
Mask decoder
이미지 임베딩, 프롬프트 임베딩, 출력 토큰을 마스크에 매핑
transformer decoder block을 수정하여 사용
dynamic mask prediction head 사용
decoder block은 prompt self-attention, cross-attention(prompt-to-image embedding and vice-versa)을 사용하여 모든 임베딩 업데이트
임베딩을 업샘플링하고 MLP가 output token을 linear classifier에 매핑한 후 각 이미지에서 mask 확률 계산
Resolving ambiguity
모호한 프롬프트가 주어지면 모델은 여러 개의 valid mask를 평균화함
단일 프롬프트에 대해 여러 output mask를 예측하도록 모델을 수정
3개의 mask 출력이면 대부분의 경우 해결가능
훈련 중에는 mask에 대한 minimum loss만 backpropagation 시 사용
mask의 순위를 매기기 위해 모델은 각 mask에 대한 IoU 예측
Efficiency
prompt encoder, mask decoder는 CPU에서 50ms 이내에 실행
Losses and training
focal loss와 dice loss의 linear 조합으로 mask prediction 설계
'공부 > 논문' 카테고리의 다른 글
