-
Chapter2 왜 현재 AI가 가장 핫할까?교육/혁펜하임의 AI DEEP DIVE 2023. 1. 27. 06:31728x90
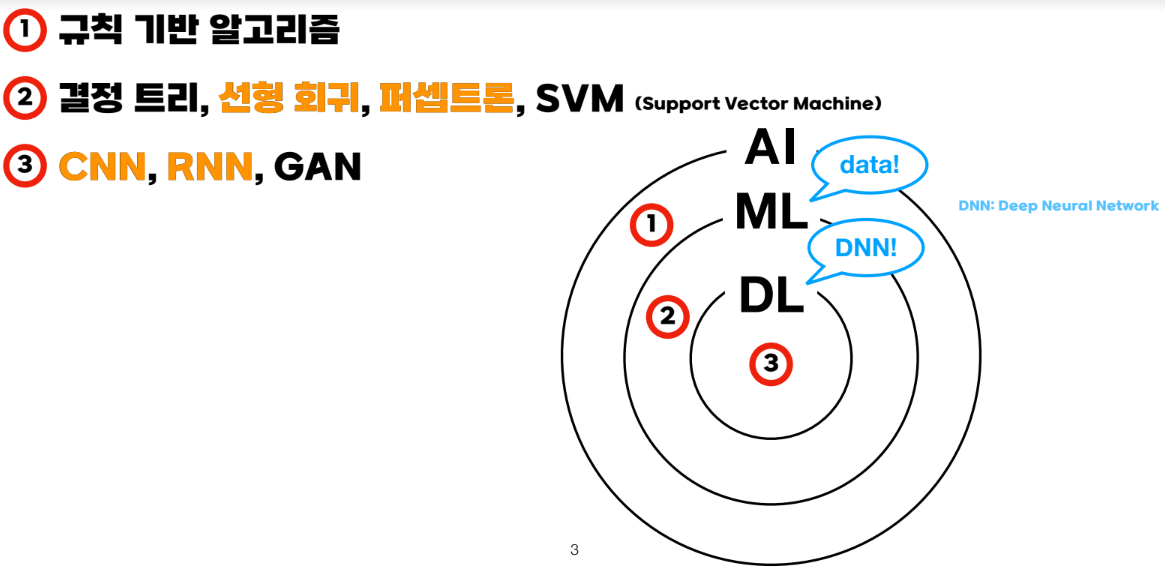
Chapter2-1 AI vs ML vs DL(Rule-based vs Data-based)
인공지능이란?인간의 지능을 인공적으로 만든 것->인간의 사고방식을 흉내
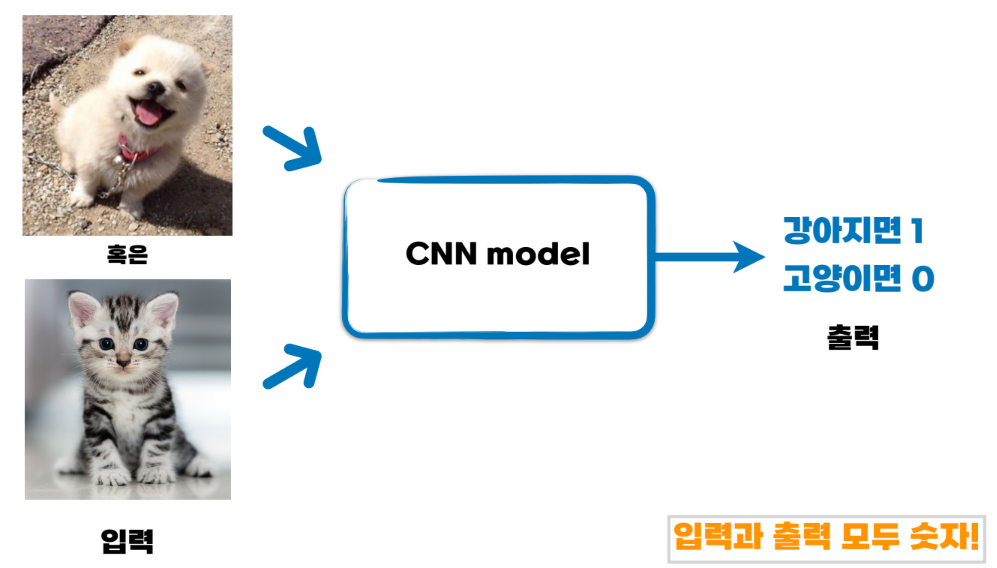
Chpater2-2 딥러닝의 활용 CNN, RNN, GAN
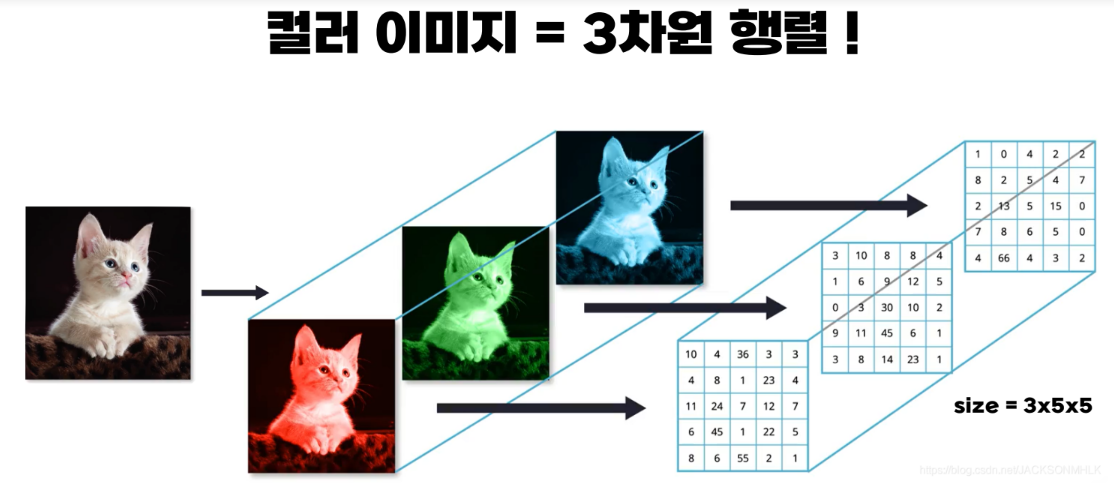
size=rgb갯수(채널갯수)*행*렬


chapter2-3 머신러닝의 분류 지도학습과 비지도학습
지도학습
정답(label)을 알고있음
ex)회귀, 분류
비지도 학습
정답(label)을 모름
ex)군집화(K-means, DBSCAN,...),차원축소(데이터 전처리:PCA, SVD, ...), GAN
chapter2-4 자기지도학습
데이터는 많을수록 좋은데 정답을 아는 데이터가 너무 적다
자기지도학습은 진짜 풀려고 했던 문제 말고 다른 문제를 새롭게 정의해서 먼저 풀어봄
데이터 안에서 self로 정답(label)을 만듦
1.preteext task학습으로 pre-training
2.downstream task(분류)를 풀기 위해 transfer learning
(pretext task로 context prediction제안)

chapter2-5 강화학습
- Agent : 학습하는 대상
- Environment : Agent와 상호작용하는 환경
- State : Agent가 필요한 구체적 정보
- Observation : Agent가 state 중 일부를 받는데 이 정도를 observation
- Policy : Agent가 움직이는 행동 방향
- deterministic policy : 해당 state에 따라 100%확률로 action이 mapping되는 a = ㅠ(s)
- stochastic policy : state가 주어졌을 때 action이 확률 적으로 선택 a = ㅠ(a|s)
- 강화학습의 목적은 결국 optimal policy(accumulative reward=return을 최대화하는 policy)를 찾는것
- Action : Agent가 실제 행동한 내용, Policy에 의해 도출되고 a로 표시
- Reward : Agnet가 행동을 했을 떄 받게되는 보상(scalar)
- Return : G_t로 표현, agent가 time step t로부터 앞(t+1)으로 받게될 discounted Reward의 누적합
- Exploration : 탐험, Agent가 현재 알고있는지식으로 행동을 하지 않고 모르는 분야로 나아가 정보를 얻기 위해 행동하는 것
- Exploitation : 활용, exploration의 반대, Agent가 아는 지식으로 행동함
- Episode : Agent가 state들을 돌아다니며 결국 terminal state에 도달했을 떄 Episode가 끝났다고 함(몇 번 시도?)
본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.
'교육 > 혁펜하임의 AI DEEP DIVE' 카테고리의 다른 글
Chapter6 인공신경망, 그 한계는 어디까지인가? (0) 2023.02.06 Chapter5 이진분류와 다중분류 (0) 2023.02.05 Chapter4 딥러닝, 그것이 알고싶다. (0) 2023.02.02 Chapter3 왜 우리는 인공신경망을 공부해야하는가? (0) 2023.01.27 Chapter1 딥러닝을 위한 필수 기초 수학 (0) 2023.01.23