-
220517-CNN교육/서울 ICT AI서비스 기획과정 2022. 5. 23. 13:08728x90
1. CNN?
Convolutional Nerual Network
기존의 Neural Network 앞 부분에 convolution layer를 추가한 것
동물의 시신경을 모방
데이터를 feature(특징, 차원)로 추출하여 패턴을 파악하는 구조
CNN의 기본구조
이미지의 특징을 추출하는 단계(Covolution Layer+Polling Layer)와 클래스를 분류하는 단계(Fully Connected Layer)를 하나의 단계로 통합한 모델
CNN의 핵심 아이디어 3가지
- Sparse interactions(sparse weight) : layer와 layer간 모든 connection을 연결하는 대신 일부만 연결
- Parameter sharing : 가중치들을 각각 다른 random variable로 취급하여 따로 update하는 대신 특정 가중치 그룹들은 가중치값이 항상 같도록 파라미터를 공유
- Equivariant representations : 이미지가 shift되어도 동등한 결과를 낼 수 있도록 설계, 공유된 파라미터가 각각의 convolution에 대해 같은 필터 처리를 하므로 만약 이미지가 shift되더라도 feature map의 형태가 크게 뒤틀리는 것이 아니라 feature map도 이미지와 함께 shift
FCNN(Fully Connected Neural Network) vs CNN(Convolution Neural Network)
- 각 레이어의 입출력 데이터 형상 유지
- 이미지의 공간 정보를 유지하면서 인접 이미지와의 특징을 효과적으로 인식
- 복수의 필터로 이미지의 특징 추출 및 학습
- 추출한 이미지의 특징을 모으고 강화하는 Pooling layer사용
- 필터를 공유파라미터로 사용하기 때문에 일반 neural network와 비교하여 학습할 파라미터가 매우 적음
2. Convolution Layer
합성곱 연산(Convolution operation)
- Convolution이란 signal processing 분야에서 많이 사용하는 operation
- 주어진 데이터 x에 filter w를 사용해 데이터를 처리할 때 사용
- 어떤 필터를 사용하여 주어진 이미지의 적절한 feature를 추출하기 위한 방법
- CNN의 핵심 아이디어는 prerpocessing이 실제 performance에 크게 영향을 미치므로 가장 좋은 feature map을 뽑아주는 convolution filter를 학습하는 모델을 만드는 것
- CNN에서 Convolution연산은 필터 연산, 필터를 이동시켜가며 이미지와 곱한 결과를 적분(덧셈)해 나감
채널(Channel)
컬러 이미지는 천연색을 표현하기 위해 각 픽셀을 RGB 실수로 표현한 3차원 데이터, 즉 컬러 이미지는 3개의 channel
흑백 이미지는 명암만을 표현하기때문에 2차원 데이터 1개의 channel로 구성
필터(filter)&Stride
Filter란 이미지의 특징을 찾아내기 위한 공용 파라미터로 Kernel이라고도 함
CNN의 학습 대상은 필터 파라미터
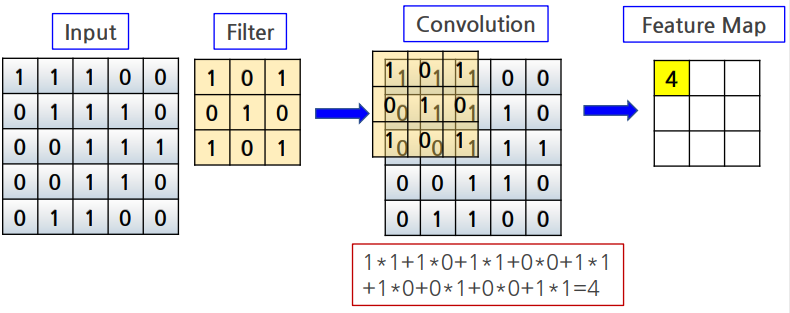
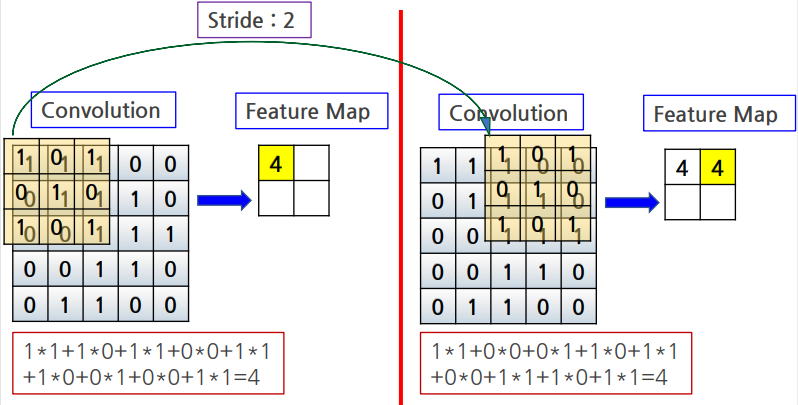
Covolution연산시, 지정한 간격으로 filter가 입력데이터를 순회
filter를 적용하는 위치의 간격을 stride라고 함
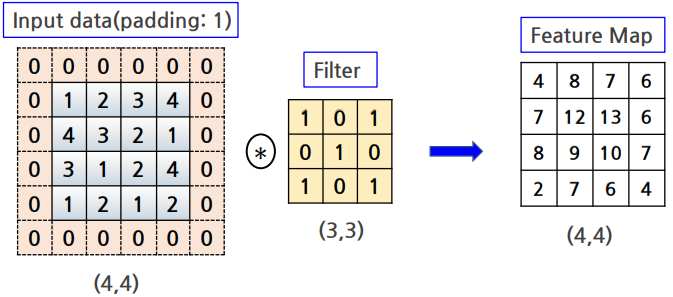
패딩(Padding)
Covolution 레이어에서 filter와 stride작용으로 인하여 feature mep의 크기는 입력 데이터보다 작아짐
convolution연산을 몇번이나 되풀이하는 심층 싱경망에서는 문제가 될 수도
padding은 주로 출력 크기를 조정할 목적으로 사용함
출력 데이터 크기 산정
stride를 키우면 출력의 크기는 작아지고 padding을 크게하면 커진다
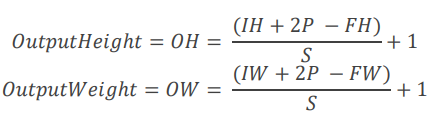
입력크기(IH, IW), filter크기(FH, FW), padding(P), stride(S)라고 할 때 출력의 크기(OH,OW) 결과는 자연수여야함, 정수로 나눠 떨어지는 값이어야함
convolution layer 다음에 pooling layer가 온다면 feature map의 행과 열 크기는 pooling 크기의 배수여야함
ex)pooling 사이즈가 (2,2)라면 feature map의 크기는 2의 배수
이 조건을 만족하도록 filter 크기, stride 간격, padding 크기, pooling 크기 조절
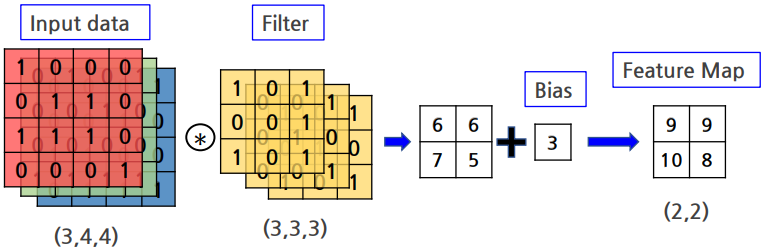
3차원 데이터(3개의 channel) Convolution연산
기본적인 이미지 처리를 위해서는 세로,가로, channel까지 고려하여 3차원 데이터를 다루어야함
channel쪽으로 feature map이 여러개 있다면 입력 데이터와 filter의 convolution연산을 channel마다 수행하고 그 결과를 더해 하나의 feature map을 얻음
입력 데이터 channel수와 filter channel수는 같아야한다. filter의 크기는 원하는 값으로 설정가능

편향(bias)
Fully connected network에는 가중치와 바이어스가 존재
CNN에서는 filter의 파라미터가 그동안의 가중치
바이어스는 필터를 적용한 후 더해짐
바이어스는 항상 하나만 존재하고 filter를 적용한 모든 원소에 더함
활성화 함수-Relu
Rectified Linear Unit
기존의 선형함수를 개선한 함수
gradient vanishing문제 해결, 계산이 쉬움
convolution연산 후 활성화 함수로 주로 사용
입력이 0보다 작으면 0, 0보다 크면 입력값 그대로 출력
3. Pooling Layer
convolution layer의 출력데이터를 입력으로 받아 크기를 줄이거나 특정 데이터를 강조하는 용도
ex)Max Pooling, Average Pooling 등
일반적으로 pooling의 윈도우 크기와 stride는 같은 값으로 설정하여 모든 원소가 한번씩 처리되도록 설정
Pooling Layer특징
- 학습해야할 매개변수가 없음 : 대상 영역에서 최댓값이나 평균을 취하는 명확한 처리, 학습할 것이 없음
- 채널수가 변하지 않음 : 입력데이터 채널 수 그대로 출력 데이터로 내보냄 채널마다 독립적으로 계산
- 입력의 변화에 영향이 적음 : feature map이 이동과 왜곡에 대해 강인하도록 하는 효과
4. CNN 성능 높이기
Batch Normalization
학습의 효율을 높이기 위해 도입, 딥러닝 속도를 더 빠르게 만들기 위해 만듦
기존방법의 문제
딥러닝 학습시 gradietn descent method사용, 속도를 높이는 가장 순진한 방법은 learning rate를 높이는 것이지만
높은 learning rate는 보통 gradient vanishing또는 gradient exploding 문제를 야기
layer가 뒤로 갈수록 분포가 변화하여 출력층에 좋지 않은 영향을 끼치게 되어 위와 같은 문제를 야기
->각 네트워크의 distribution을 같게 하는 방법을 고안
알고리즘
학습 시 미니배치를 한 단위로 정규화
분포의 평균이 0, 분산이 1이 되도록 정규화->데이터 분포가 덜 치우침
배치 정규화 단계마다 확대 scale과 이동 shift변환(transform)을 수행
이점
- 가장 궁극적인 목표는 internal covariate shift를 줄이는 것, 신경망의 각 레이어의 분포를 같게 함으로써 좀 더 안정적인 학습이 가능
- 학습 속도 개선(학습률 높게 설정가능)
- 가중치 초기값 선택의 의존성이 적어짐(학습할때마다 출력값 정규화)
과적합 위험 줄임(dropout 대체 가능) - gradient vanishing문제 해결
- BN을 추가한 네트워크는 각각의 layer input앞에 batchnormalization layer라는 layer를 추가한 것과 동일한 구조
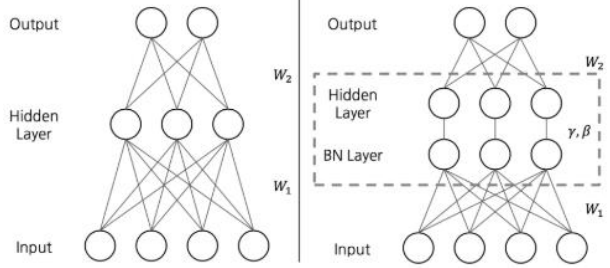
- Hidden layer에서 정규화를 하면서 입력 분포가 일정하게 되고, 이에 따라 learning rate를 크게 설정해도 괜찮아지며 결과적으로 학습속도가 빨라짐
- 학습을 할 때 hidden layer의 중간에서 학습할 때마다 입력 분포가 변화하면서 가중치가 엉뚱한 방향으로 갱신되어 신경망 층이 깊어질 수록 엉뚱한 학습이 될 수 있음
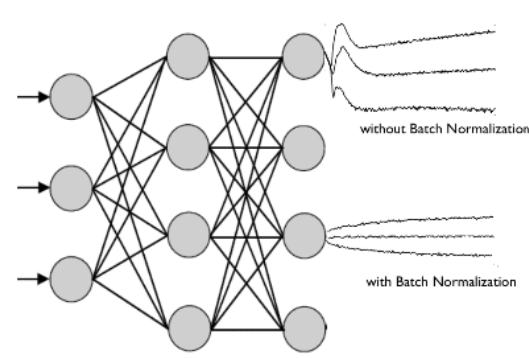
- BN은 입력분포를 정규화하기 때문에 보다 안정적
5. CNN의 발전
1. LeNet

CNN을 최초로 개발한 교수의 연구 그룹이 최종적으로 발표한 구조
단순한 형태, 6개의 hidden layer사용
구조
Conv filters:5*5, stride : 1 / Polling layer : 2*2, stride : 2 / 구조 : conv->pool->conv->pool->conv->FC
2. AlexNet
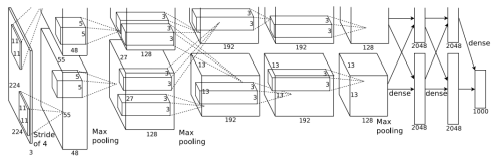
GPU를 사용하여 의미있는 결과를 얻음
구조
2개의 GPU를 기반으로 한 병렬 구조
Conv layers: 5, Full-connected layers:3, 마지막 FC layer는 1000개의 카테고리 분류를 위해 softmax함수 사용
성능 개선을 위해 활성함수로 Relu함수 사용
LeNet-5는 average pooling, AlexNet은 max pooling사용
더보기average에 비해 최대값을 구해야하기 때문에 연산양은 더 많지만, 최대 크기를 갖는 자극만 전달한다는 관점은 생물학적인 특성과 좀 더 유사
첫번째 두번째 convolution결과에 ReLU수행 후 maxpooling을 하기때문에 앞서 response normalization을 수행하여 출력에 대한 정규화를 수행함으로써 에러율 개선
Overfitting 개선 - data argumentation
파라미터 개수가 6000만개이상이므로 많은 양을 학습하다 보면 overfitting으로 고생
해결방법
1. 학습 영상의 수를 늘리는 data argumentation과 망의 일부를 생략하면서 진행하는 dropout사용
256*256크기의 원영상으로부터 무작위로 224*224크기의 영상을 취하고 1장의 학습 영상으로 부터 2048개의 다른 영상 추출
Test시에는 5개의 224*224영상(상하좌우중앙)과 그것들을 수평으로 반전한 이미지 5개 총 10개로부터 softmax출력을 평균하는 방법을 택함
2. 각 학습 영상의 RGB채널값을 변화
학습 이미지의 RGB픽셀 값에 대한 주성분 분석(PCA)수행 후, 거기에 평균 -, 표준편차 0.1크기를 갖는 랜덤 변수를 곱하고 그것을 원래 픽셀값에 더해주는 방식으로 컬러 채널의 값을 바꾸어 다양한 영상을 얻게됨
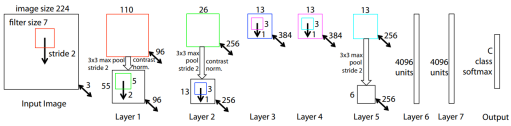
3. ZFNet

CNN을 보다 잘 이해할 수 있는 기법
AlexNet의 기본 구조를 Visualizing기법을 통해 개선할 수 있음을 보여줌
구조
AlexNet은 일부 feature에 몰리는 현상, aliasing문제도 발생/ZFNet은 다양한 feature가 고르게 나타남

b,d는 AlexNet, c,e는 ZFNet AlexNet의 이런 현상은 큰 stride를 사용했기 때문이라고 분석
AlexNet : 필터 크기=11*11 stride=4 ->ZFNet: 필터크기=7*7 stride=2로 변경해서 학습
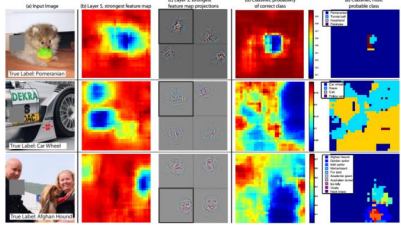
Deconvolution Network을 이용한 Visualization
Deconvolution Network?
Deconvnet은 Convnet과 완전히 동일한 구성요소로 이루어져있지만 반대의 순서로 행해짐, featrue map을 input으로 받아서 image level에 반영하는 형태
- 분석하고자 하는 특정 Conv Layer의 특정 Filter Activation 선정
- 해당 Filter Activation을 제외한 모든 output을 0으로 세팅한 상태로 deconvnet에 input으로 입력
- Neural Network Architecture 순서의 반대로 아래의 3가지 deconvolution 수행
- Unpooling : Max-pooling된 지점 저장해두고, unpooling할 때는 해당 지점을 이용해서 재생성
- Rectification : ReLU를 통해 양수로 Activation된 값은 그대로 두고 음수는 재생성 불가능하므로 그대로 0으로 둠
- Filtering : convolution filter값의 transposed된 matrix사용
->Reconstruction된 것으로 입력으로 주어진 input image의 일부와 유사할 수 밖에 없으며 이를 통해 어떤 파트를 통해 Neural Network가 결과를 내었는지 분석가능, Layer가 높을 수록 높은 추상화가 된 걸 알 수 있으며, 비슷한 클래스에 대한 불변성도 볼 수 있음
Feature Invariance?
이미지를 변형(translate, scale, rotation)했을 때 network 결과의 변화
translate, scale에 상대적으로 강하고 rotation에 상대적으로 취약
Convolution Network Visualization
학습하는 동안 Feature Evolution
학습이 진행되면서 feature map이 어떻게 변하는 지를 보여줌, 시간이 지나면서 선명도가 증가하고 특정한 모양에 활성화되는 형태로 발전
민감도 분석(Sensitivity Analysis)
Network모델이 정말로 object의 위치를 확인하여 인식하는지, 주변 환경을 활용하여 인식하는지 확인
회색 사각형으로 이미지의 각 부분을 가려보고 classifier의 output을 관찰
4. GoogLeNet
CNN에서 네트워크가 깊어질수록 성능이 좋아지지만 네트워크가 깊어질수록 학습해야할 파라미터 수가 늘어남
- 학습에 사용할 데이터 양이 제한적인 경우 overfitting에 빠질 가능성이 높음
- 망의 크기가 커질수록 연산양도 늘어나게 되는데 예를 들어 필터의 개수가 증가하게 되면 연산양은 제곱으로 늘어남 ->연산 능력이 뛰어난 GPU를 사용하더라도 이런 연산양 증가는 문제
=>Inception이라는 개념을 통해 위의 문제들 어느정도 해결
구조

레이어 초반에는 인셉션 모듈이 들어가지 않는데 실험결과 초반 레이어에는 인셉션이 효과가 없어서 뺐다고 함
결과를 추출하는 softmax가 중간 중간있는데 이를 논문에서는 auxiliary classifier라 부름, loss를 맨 끝만 아니라 중간중간 구하기 때문에 gradient가 적절하게 역전파되고 vanishing gradient의 문제 해결
NiN(Network in Network)
일반적인 Convolution layer는 필터가 움직이면서 해당하는 입력 부분과 곱/합 연산을 수행하고 활성화함수를 거쳐 결과를 만들어냄
만약 데이터 분포가 비선형적인 관계라면 표현할 수 있도록 NiN논문에서는 단순한 곱/합 연산이 아니라 Multi Layer Perceptron 즉, 중간에 MLP를 추가
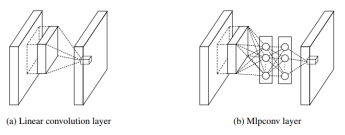
MLPConv는 일반적인 convolution연산을 거치고 마지막에 하나의 값으로 매핑하는 cccp(Cascaded Cross Channel Pooling)을 수행

n개의 레이어를 사용하는 MLP Conv는 일반적인 Convolution 연산을 적용한 다음 필터가 1*1 Convolution을 적용한 것과 동일
NiN의 목적이 MLP를 도입하여 비선형적인 관계를 더 잘 표현하는 것이었으므로, CNN에 MLP의 도입도 1*1Conv르 ㄹ적절하게 사용하면서 비선형적 함수를 더 잘 만들어낼 수 있게 됨
1*1 Conv는 채널단위에서 pooling을 해주기 때문에 1*1 Conv의 수를 입력채널보다 작게하면 차원 축소도 가능
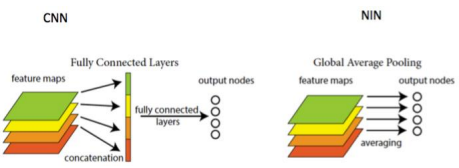
Average pooling
마지막 MLP Conv layer에서 classification해야할 만큼 feature map을 생성한 후 average를 계산하여 바로 softmax layer에 전달함으로써 파라미터수를 감소시키며, 오버피팅을 방지
인셉션(Inception) 모듈
feature를 효율적으로 추출하기 위해 1*1, 3*3, 5*5의 convolution연산을 병렬 수행하는 inception모듈 도입
깊이가 깊어질수록 연산량이 많아지는 문제에 봉착
->1*1 conv를 추가하여 차원 축소를 수행, 1*1 conv에 넣어 channel을 줄였다가 3*3이나 5*5 conv거치면서 다시 확장
4. VGGNet
간단한 구조, 단일 네트워크에서 좋은 성능 등을 이유로 여러 응용 분야에서 기본 네트워크로 많이 사용됨
AlexNet과 전반적인 구조는 비슷하나 깊이에서 확연하게 차이
오직 깊이가 어떤 영향을 주는 지 찾기 위해, filter의 크기는 간단한 3*3으로 정하고 깊이가 어떤 영향을 주는지 6개의 구조에 대해서 실험
구조
224*224크기의 color이미지를 입력으로 받아 한개 혹은 그 이상의 convolution layer뒤에 max pooling layer가 오는 단순한 구조
기존의 conv net들은 대체적으로 큰 필터를 사용했지만 VGGNet은 모든 레이어에서 가장 작은 크기의 필터 사용(3*3, s=1,p=1) 이때 3*3필터로 구성된 레이어 2개를 쌓으면 5*5와 동일한 성능을 3개를 쌓으면 7*7과 동일한 성능을 보임
3*3필터의 장점
- 여러개의 ReLU non-linear를 사용 : 큰 필터로 구성된 하나의 레이어를 작은 필터의 여러 레이어로 나누었기 때문에 Relu가 들어갈 곳이 많아지고 이는 결과가 더 변별력 있다는 말
- 학습해야할 weight 수 감소 : 7*7 conv layer의 파라미터 개수는 7^2*C^2=49C^2임 반면 3*3 conv layer 3개는 3*(3^2*c^2)=27C^2이므로 학습해야할 파라미터 개수가 적어 정규화 측면에서 큰 이점을 보임
data argumentation
AlexNet이 시행한 두가지 augmentation방법을 기본적으로 따름
data argumentation-rescaling
원본 이미지르 ㄹ잘라내기 전에 먼저 이미지를 가로, 세로가 원본과 동일한 비가 되도록 scaling하고 이 rescale된 이미지에서 학습할 224*224크기의 이미지들을 추출
Rescale된 이미지 크기(w,h 중 작은 값)을 S
S를 설정하는 방법
- Single-scale learning : S값을 고정된 크기로 정하는 것, 논문에서는 S=256, 284 두가지 값으로 설정, 네트워크 훈련 시 먼저 S=256크기의 이미지를 통해 일차적으로 훈련, S=384크기의 네트워크 훈련 시 S=256인 네트워크의 초기값을 이용하여 학습속도를 향상시키고 더 작은 learning rate(10^-3)을 사용하여 학습 진행
- Multi-scale learning : S값을 최소값과 최대값 사이에서 랜덤으로 선택하고 이 값을 통해 이미지를 scale, 최소값은 256, 최대값은 512로 이 방법은 원본 이미지에 있는 물체가 랜덤한 크기를 가질 수 있으므로 다양한 입력 변화를 줄 수 있음, 훈련시 먼저 S=384인 Single-scale learning 네트워크를 학습시키고, 학습된 네트워크의 초기값을 적용하여 fine-tuning함
5. ResNet-Residual learning
기존의 stacking된 네트워크에 일종의 skip connection을 추가한 것
2개의 layer를 거친 output에 input을 그대로 더해주는 형태로 구성
마지막 output=H(x), Stacking된 layer의 output=F(x), input=x라 하면 H(x)=F(x)+x형태로 block형성
Skip connection이 없었던 것에 비해 F(x)는 input과의 차이만 학습하면 됨

Bottleneck Architecture
깊게 쌓을수록 계산양이 증가
Bottleneck architecture도 1*1Conv를 활용하여 channel차원 축소를 통해 연산량을 줄임
1*1 Conv로 채널 수를 줄인 후 3*3 Conv를 통과하고 다시 1*1 Conv를 지나 채널 수를 복구
'교육 > 서울 ICT AI서비스 기획과정' 카테고리의 다른 글
220517-GAN (0) 2022.06.21 220516 (0) 2022.05.23 220510 (0) 2022.05.23 220509 (0) 2022.05.23 220504 (0) 2022.05.23