-
220510교육/서울 ICT AI서비스 기획과정 2022. 5. 23. 11:50728x90
유용한 모델 - Transfer Learning
Transfer Learning
- 이미 만들어진 모델을 사용하여 새로운 모델을 만드는 방법
- 학습을 빠르게 하며 예측력을 더 높일 수 있음
- 이미 학습이 완료된 모델(Pre-Trained Model)을 가지고 미세조정하고 이미 학습된 가중치들을 전송하여 자신의 모델에 맞게 학습하는 과정을 세부 조정(fine-tuning)이라 부름
Fine-tuning방법
- Feature extraction
- pre-trained model을 모델 구조를 이용
- 다른 레이어를 고정시키고 일부분 layer 조정

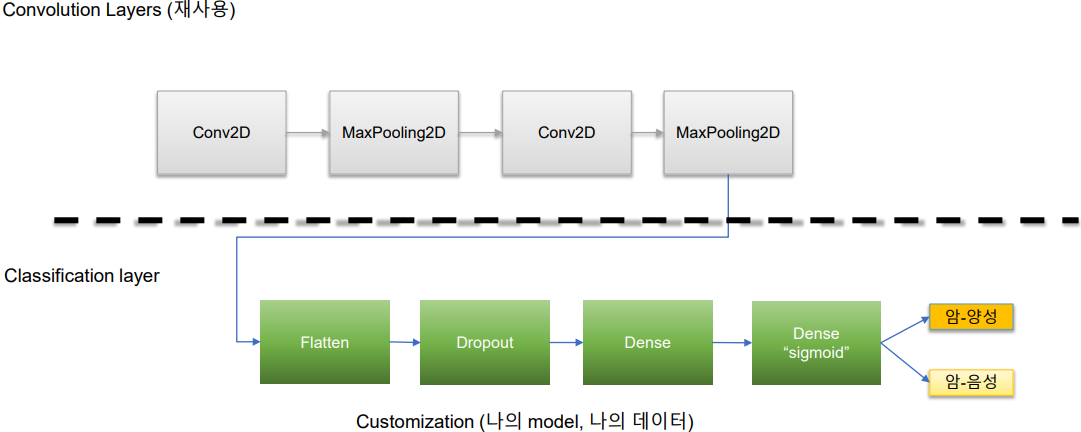
CNN에서 Transfer Learning 유용한 모델 - Language Model
Language Model의 장점
- 자연어에는 불확실성이 존재
- 특정 시퀀스가 출현할 확률로 정량화 가능
- 해당 언어모델로 텍스트 생성가능(Generative Model)
통계 기반의 언어모델(Statistical LM) vs 딥러닝 기반의 언어모델(Neural Network based LM)
통계 기반의 n-Gram 언어모델
- 모든 단어를 고려하는 것이 아니라 n개의 단어만 고려
- 단점 : n이라는 숫자, 적용분야에 따라 다름, 도메인 특화된 corpus필요
딥러닝 기반의 언어모델
- 문장에 있는 단어들을 RNN, LSTM으로 학습하여 예측
- 획기적인 성능 개선
Word Embedding
단어를 벡터로 표현
Word2Vec
- 유사도, 관계표시가능, 단어들에 대한 vector 연산가능
- CBOW : 둘러쌓인 단어에서 앞 뒤 문장의 의미 유추
- Skip-gram : 단어에서 앞 뒤 문장 의미 유추
- 단점 : 서울-서울시 같은 단어를 다른 단어로 인식
GloVe(Global Vectors for Word Representation)
- 단어들의 관계에 대한 가중치로 의미 파악
ELMo(Embeddings from Language Model)
- pre-trained language model사용(Transfer Learning 활용)
- word2vec방식 개선하여 문맥 반영한 word embedding(contextualized word embedding)
- 이미 많은 단어들을 대상으로 Bi-LSTM으로 학습한 pretrained model을 활용해서 다음 단어를 softmax로 예측(T1~Tn)
- QnA, NER, Sentiment Analysis에서 좋은 성능 발휘
UMAP(Uniform Manifold Approximation and Projection)
Topological data analysis로 아이디어와 manifolde learninig기술을 기반으로 차원 축소 알고리즘
고차원 데이터를 데이터 공간에 뿌리며 샘플들을 잘 아우르는 subspace가 있을것이라는 가정하에 학습


t-SNE(Stochastic Neighbor Embedding)
고차원 데이터를 2차원 지도로 표현

Transformer
- 문장의 단어들을 병렬로 처리
- 단어의 의미가 앞뒤문장의 위치에 따라서 변할 수 있으므로, 문장내의 단어들의 위치를 숫자로 표현(positional encoding)
- 전체 입력 문장 중에서 중요한 부분에 포커스(attention function)
기존 번역 모델의 문제점
- Long-term dependency problem : 기존의 recurrent model은 문장의 순차적인 특성을 살릴 수 있지만 여전히 Long-term dependency problem존재
- Parallelization : 순차적인 특성 때문에 병렬처리 불가, 연산속도 느림
- Self-attention : 원본 언어와 번역된 언어 간의 관계는 기존의 Attention mechanism으로 찾을 수 있지만, 원본 언어 혹은 번역된 언어 내에서의 관계는 나타낼 수 없음
->가존 번역 모델의 문제점들을 해결하고 Reucurrent/Covolution없이 Self-Attention으로만 이루어진 최초의 번역 모델 : Transformer

인공지능의 2가지 흐름
기호주의(top-down)
- 규칙, 논리 이런것들을 미리 정해놓고 rule을 만듦
- rule을 기반으로 추론엔진을 만들고 새로운 문제가 생기면 추론엔진에 의해 rule을 따라가며 답을 찾음
- ex) 전문가시스템, 의학진단 시스템
- 문제점 : rule에 없는 건?
연결주의(bottom-up)
- 인간의 신경조직을 수학적 알고리즘을 만듦
- 대량의 데이터로 학습을 시킴
- 학습된 모델로 신규데이터에 대한 답을 찾고 학습하지 않은 데이터에 대해서도 답을 찾음
- ex) 머신러닝, 딥러닝
- 문제점 : data가 너무 많이 필요함, GPU필요, 에러율 인정
=>상관관계 기반의 Neural Network
인과관계의 Causal Inference가 필요!
=>Nerurosymbolic AI
XAI(eXplanable AI, 설명가능한 AI)
기존 모델을 변형하여 각 단계를 설명하도록(deconvolution network)하여 새로운 모델 개발(원인-결과 도출하는 과정이 표현 가능하도록 설계)하고 모델 간 비교
ex) Footprint기법, 이미지 깊이 예측 네트워크(image depth prediction network), 이미지 평탄화 기술, Dreamer, VQA, SinGAN, Federated Learning
'교육 > 서울 ICT AI서비스 기획과정' 카테고리의 다른 글
220517-CNN (0) 2022.05.23 220516 (0) 2022.05.23 220509 (0) 2022.05.23 220504 (0) 2022.05.23 220503 (0) 2022.05.15