-
[8주차 - Day3] 인공지능과 기계학습 소개교육/프로그래머스 인공지능 데브코스 2021. 6. 17. 17:20728x90
1. Deep Learning: 신경망의 기초 - 인공지능과 기계학습 소개
인공지능이란?
인간의 학습능력과 추론능력, 지각능력, 자연언어의 이해능력 등을 컴퓨터 프로그램으로 실현한 기술
ex)음성인식, 추천 시스템, 자율 주행, 실시간 객체 인식, 로봇, 번역 등
2. Deep Learning: 신경망의 기초 - 기계학습 I
1. 미리보기
1.1. 기계학습의 정의
인공지능(artificial intelligence) : 인간의 학습, 추론, 지각, 자연언어 이해 등의 지능적 능력을 기기로 실현한 기술
학습 : 비교적 지속적인 행동의 변화나 그 잠재력의 변화, 지식을 습득하는 과정
기계학습(machine learning) : 컴퓨터가 경험(=데이터)을 통해 학습하여 최적의 프로그램(알고리즘)을 찾는 행위
1.2. 지식기반 방식에서 기계 학습으로의 대전환
초창기에는 지식기반 방식(사람이 아는 규칙)을 컴퓨터에게 부여하여 학습
지식기반 방식의 한계 : 모든 지식의 나열은 불가능
기계학습->심층학습(deep learning, or 표현학습=representation learning)으로 발전
즉, 데이터 중심 접근 방식으로 전환
1.3. 기계 학습 개념
훈련집합(training set) : 학습을 가능하게 하는 데이터
훈련집합을 통해 가설을 만듦
훈련(train) : 가설의 모델을 수식으로 나타내고 수식의 매개변수를 찾아내는 작업
추론(inference) : 새로운(unknown) 특징에 대응되는 목표치의 예측에 사용
기계학습의 궁극적인 목표 : 훈련집합에 없는 새로운 데이터에 대한 오류를 최소화, 일반화(generalization)능력 향상
필수요소 : 학습할 데이터+데이터 규칙+규칙이 수학적으로 설명 불가능해야함
2. 특징 공간에 대한 이해
2.1. 1차원과 2차원 특징 공간
모든 데이터는 정량적으로 표현되고 특징 공간 상에 존재
2.2. 다차원 특징 공간
d-차원 데이터 : 특징 벡터로 표기 x=(x1, x2, ... , xd)^T
2.3. 특징 공간 변환과 표현 학습
차원의 저주(curse of dimensionality(=number of features))
차원이 높아질수록 유의미한 표현을 찾기 위해 지수적으로 많은 데이터가 필요
표현 학습(representation learning) : 선형 분리 불가능(linearly non-sperable)한 원래 특징 공간을 공간 변환을 통해 새로운 특징 공간으로 바꾸고 모델을 추론하면 정확도가 향상되는데 좋은 새로운 특징 공간을 자동으로 찾는 작업
심층학습(deep learning) : 표현 학습의 하나로 다수의 은닉층을 가진 신경망을 이용하여 최적의 계층적인 특징을 학습
3. Deep Learning: 신경망의 기초 - 기계학습 II
3. 데이터
3.1. 데이터에 대한 이해
데이터 수집->모델 정립(가설, hypothesis)->예측
3.2. 데이터의 중요성
주어진 과업에 적합한 다양한 데이터를 충분한 양만큼 수집하면 과업의 성능은 향상됨
3.3. 데이터베이스 크기와 기계 학습 성능
데이터의 적은 양 -> 차원의 저주
데이터 희소(data sparsity)특성 가정 : 쓸데없는 데이터가 생길 확률은 적다
매니폴드 가정(manifold assumption) : 고차원의 데이터는 관련된 낮은 차원의 매니폴드에 가깝게 집중
3.4. 데이터 가시화
4차원 이상의 초공간(hyperplane)은 한꺼번에 가시화(visualization)불가능->조합해서 여러개로 보여준다든가 하는 방법 존재
4. 간단한 기계 학습의 예
4.1. 선형 회귀(linear regression)
직선 모델(=가설)(y=wx+b)을 사용하므로 두 개의 매개변수(w, b)가 존재
목적 함수(objective function, or 비용함수(cost function)) : 성능을 정량적으로 측정하는 함수
평균제곱오차(MSE, Mean Squared error)
선형 회귀를 위한 목적 함수
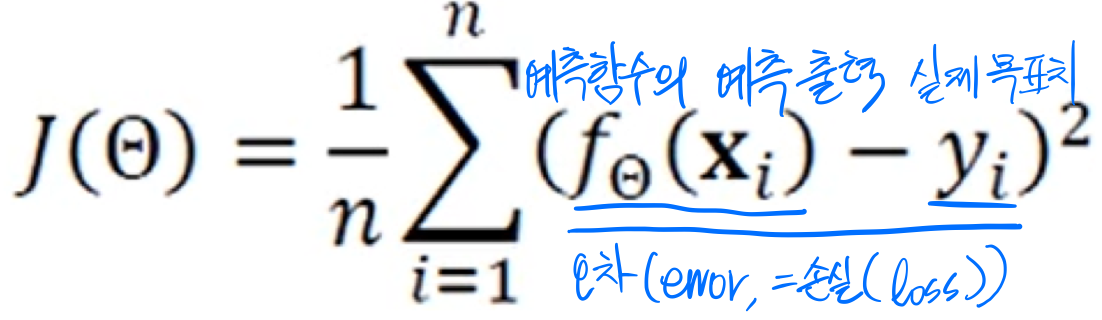
평균제곱오차(MSE, Mean Squared Error)
선형 회귀를 위한 목적 함수
처음에는 최적의 매개변수 값을 알 수 없기 때문에 임의의 난수로 설정
기계학습은 작은 개선을 반복하여 최적의 해를 찾아가는 수치적 방법으로 식을 품
4.2. 현실
위의 예시는 데이터가 선형으로 이루는 단순한 상황
현실 세계는 선형이 아니고 잡음이 섞이므로 비선형 모델이 필요
4. Deep Learning: 신경망의 기초 - 기계학습 III
5. 모델 선택
5.1. 과소적합과 과잉적합
과소적합(underfitting) : 모델의 용량이 작아 오차가 클 수 밖에 없는 현상
과잉적합(overfitting) : 모델의 용량이 크기 때문에 잡음까지 수용해서 새로운 데이터를 예측할 때 문제가 발생
=>적절한 용량의 모델을 선택하는 모델 선택 작업이 필요
5.2. 편향(bias)과 분산(variance, or 변동)
차수가 낮으면 매번 큰 오차->편향이 크지만 비슷한 모델을 얻으므로 분산이 낮음
차수가 높으면 매번 작은 오차->편향이 작지만 다른 모델을 얻으므로 분산이 높음
=>일반적으로 용량이 적으면 편향이 크고 분산이 작음, 복잡한 모델은 편향이 작고 분산이 큼

기계학습의 목표 : 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표
5.3. 검증집합과 교차검증을 이용한 모델 선택 알고리즘
- 훈련 집합과 테스트 집합과 다른 별도의 검증집합(validation set)을 만들어서 학습
- 데이터 양이 많을 때 사용
- 교차검증(cross validation)
- 별도의 검증집합이 없는 상황에 유용한 모델 선택기법으로 훈련집합을 등분하여 학습과 평가과정을 여러번 반복
- 훈련 집합을 k개의 그룹으로 나누고 i번째 그룹을 제외한 k-i개로 학습시키고 i번째 그룹으로 성능 측정을 k번 반복하여 가장 높은 성능을 보인 모델 선택, 중복허용X
- 데이터 야잉 적을 때 사용
- 부트스트랩(bootstrap)
- 임의의 복원 추출 샘플링(samplin with replacement)반복, 데이터 분포가 불균형할 때 사용
- 훈련 집합에서 샘플을 뽑아 새로운 훈련집합을 만들어 훈련시키고 훈련집합-새로운 훈련집합의 집합으로 모델 성능 측정을 N번 반복하여 가장 높은 성능을 보인 모델 선택, 중복허용O
- 데이터 분포가 불균형일 때 사용
5.4. 모델 선택의 한계와 현실적인 해결책
용량이 충분히 큰 모델을 선택한 후 모델이 정상을 벗어나지 않도록 여러 규제(regularization)기법을 적용
6. 규제
6.1. 데이터 확대
데이터를 더 많이 수집하면 일반화 능력이 향상됨 하지만 수집은 비용이 많이 듦->인위적으로 데이터 확대(data augmentation) 훈련집합에 있는 샘플을 변형(transform)
6.2. 가중치 감쇠
개선된 목적함수를 이용하여 가중치를 작게 조절하는 규제 기법
목적함수에 패널티항을 추가함으로써 적용

7. 기계 학습 유형
7.1. 지도 방식에 따른 유형
- 지도 학습(supervised learning)
- 특징 벡터 X와 목표치Y가 모두 주어진 상황(정답이 있음)
- 회귀(regression)와 분류(classification)으로 구분
- 비지도 학습(unsupervised learning)
- 특징 벡터 x는 주어지는데 목표치 y가 주어지지 않는 상황(정답이 없음)
- 군집화(clustering), 밀도추정(density estimation), 특징 공간 변환
- 강화 학습(reinforcement learning)
- 목표치가 주어지는데 보상(reward)으로 주어짐
- 준지도 학습(semi-supervised learning)
- 일부는 x와 y를 모두 가지지만 나머지는 x만 가지는 상황
- 대부분의 데이터가 x의 수집은 쉽지만 y는 수작업이 필요하여 최근 중요성이 부각
7.3. 다양한 기준에 따른 유형
1. 오프라인/온라인
- 오프라인 학습(offline learning) : 보통의 경우, 데이터를 수집해놓고 그 안에서 학습을 수행
- 온라인 학습(online learning) : 추가로 발생하는 데이터 샘플을 가지고 점증적 학습 수행
2. 결정론적/확률적
- 결정론적 학습(deterministic learning) : 같은 데이터를 가지고 다시 학습하면 같은 예측 모델이 만들어짐
- 확률적 학습(stochastic learning) : 학습 과정에서 확률 분포를 사용하므로 같은 데이터로 다시 학습하면 다른 예측 모델이 만들어짐
3. 분별/생성
- 분별 모델(discriminative models) : 부류 예측에만 관심, P(y|x)(=데이터가 들어왔을 때 타겟을 예측하는 규칙, x가 y가 되는 상관관계)의 추정에 관심
- 생성 모델(generative models) : 새로운 샘플을 생성할 수 있음, P(x)또는 P(x|y)를 추정 ex)GAN
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[9주차 - Day1] 신경망 기초 (0) 2021.06.23 [8주차 - Day4] 기계학습과 수학 리뷰 (0) 2021.06.18 week6~week8 day2 (0) 2021.06.15 [7주차 - Day2] ML_basics - Probability Distributions (Part 2) (0) 2021.06.10 [7주차 - Day1] ML_basics - Probability Distributions (Part 1) (0) 2021.06.08 - 훈련 집합과 테스트 집합과 다른 별도의 검증집합(validation set)을 만들어서 학습