-
chatper4. 임베딩공부/처음 배우는 딥러닝 챗봇 2023. 4. 13. 14:52728x90
4.1 임베딩이란?
컴퓨터는 자연어를 직접적으로 처리할 수 없음
컴퓨터는 수치연산만 가능하기 때문에 자연어를 숫자나 벡터 형태로 변환해야함
->임베딩(embedding) : 단어나 문장을 수치화해 벡터 공간으로 표현하는 과정
임베딩은 말뭉치의 의미에 따라 벡터화하기 때문에 문법적인 정보가 포함
임베딩 기법에는 문장 임베딩과 단어 임베딩이 있음
- 문장 임베딩은 문장 전체를 벡터로 표현하는 방법
- 장점1 : 문장 임베딩의 경우 전체 문장의 흐름을 파악해 벡터로 변환하기 때문에 문맥적 의미를 지님
- 장점2 : 단어 임베딩에 비해 품질이 좋으며 상용 시스템에 많이 사용
- 단점 : 임베딩하기 위해 많은 문장 데이터가 필요, 학습하는 데 비용이 많이 듦
- 단어 임베딩은 개별 단어를 벡터로 표현하는 방법
- 장점 : 문장 임베딩에 비해 학습 방법이 간단해 실무에서 많이 사용
- 단점 : 동음이의어에 대한 구분을 하지 않기 떄문에 의미가 다르더라도 단어의 형태가 같다면 동일한 벡터값으로 표현
4.2 단어 임베딩
말뭉치에서 각각의 단어를 벡터로 변환하는 기법
의미와 문법적 정보를 지니고 있으며, 단어를 표현하는 방법에 따라 다양한 모델이 존재
4.2.1 원-핫 인코딩
단어를 숫자 벡터로 변환하는 가장 기본적인 방법
명칭에서도 알 수 있듯이 요소들 중 단 하나의 값만 1이고 나머지 요솟값은 0인 인코딩
원-핫 인코딩으로 나온 결과를 원-핫 벡터라 하며, 전체 요소 중 단 하나의 값만 1이기 때문에 희소 벡터라고 함
원-핫 인코딩을 하기 위해서는 단어 집합이라 불리는 사전을 먼저 만들어야함
여기서 사전은 말뭉치에서 나오는 서로 다른 모든 단어의 집합
말뭉치에 존재하는 모든 단어의 수가 원-핫 벡터의 차원을 결정
ex)100개의 단어가 존재한다면 벡터의 크기는 100차원
사전이 구축되었다면 사전 내 단어 순서대로 고유한 인덱스 번호를 부여
단어의 인덱스 번호가 원-핫 인코딩에서 1의 값을 가지는 요소의 위치
단어 사전 내의 단어들은 각각 고유한 원-핫 벡터를 가짐
from konlpy.tag import Komoran import numpy as np komoran=Komoran() text='오늘 날씨는 구름이 많아요.' #1. 명사만 추출 nouns=komoran.nouns(text) print(nouns) #2. 단어 사전 구축 및 단어별 인덱스 부여 dics={} for word in nouns: if word not in dics.keys(): dics[word]=len(dics) print(dics) #3.원-핫 인코딩 nb_classes=len(dics) targets=list(dics.values()) one_hot_targets=np.eye(nb_classes)[targets] print(one_hot_targets)
원-핫 인코딩의 경우 간단한 구현 방법에 비해 좋은 성능을 가지기 때문에 많은 사람이 사용하고 있음
하지만 원-핫 벡터의 경우 단순히 단어의 순서에 의한 인덱스값을 기반으로 인코딩된 값이기 때문에 단어의 의만 유사한 단어와의 관계를 담고 있지 않음
또한 단어 사전의 크기가 커짐에 따라 원-핫 벡터의 차원도 커지는데 이 때 메모리 낭비와 계산의 복잡도가 커짐
원-핫 벡터는 대부분의 요소가 0의 값을 가지고 있으므로 비효율적
4.2.2 희소 표현과 분산 표현
단어가 희소벡터로 표현되는 방식을 희소표현이라 부름
희소표현은 각각의 차원이 독립적인 정보를 지니고 있어 사람이 이해하기에 직관적인 장점이 있지만 단어의 사전의 크기가 커질수록 메모리 낭비와 계산 복잡도가 커짐, 또한 단어 간의 연관성이 전혀 없어 의미를 담을 수 없음
자연어 처리를 잘하기 위해서는 기본 토큰이 되는 단어의 의미와 주변 단어 간의 관계가 단어 임베딩에 표현되어야함
이를 해결하기 위해 각 단어 간의 유사성을 잘 표현하면서도 벡터 공간을 절약할 수 있는 방법 고안
->분산 표현 : 한 단어의 정보가 특정 차원에 표현되지 않고 여러차원에 분산되어 표현된다하여 붙여진 이름
즉, 하나의 차원에 다양한 정보를 가지고 있음

위의 예시처럼 분산 표현 방식을 사용하면 단어 임베딩 벡터가 더이상 희소하지 않음
신경망에서는 분산표현을 학습하는 과정에서 임베딩 벡터의 모든 차원에 의미있는 데이터를 고르게 밀집
->희소표현과 반대로 데이터손실을 최소화하면서 벡터 차원이 압축되는 효과가 생김!
우리가 원하는 차원에 데이터를 최대한 밀집시킬 수 있어 밀집표현이라 부르기도 하고, 밀집 표현으로 만ㄴ들어진 벡터를 밀집 벡터라 함
희소 표현 방식에 비한 분산 표현 방식의 2가지 장점
- 임베딩 벡터의 차원을 데이터 손실을 최소화하면서 압축가능
- 희소 표현방식은 단어를 표현하는데 너무 많은 차원이 필요->단어 사전이 커질수록 비효율적일 수밖에 없는데다가 희소 벡터이기 때문에 대부분의 값이 0->입력 데이터의 차원이 너무 높아지면 차원의 저주 문제 발생
- 임베딩 벡터에는 단어의 의미, 주변 단어 간의 관계 등 많은 정보가 내포되어 있어 일반화 능력이 뛰어남
- 벡터 공간 상에서 유사한 의미를 갖는 단어들은 비슷한 위치에 분포되어 있기 때문에 두 단어 간의 거리를 계산할 수 있으면 컴퓨터는 두 단어를 같은 의미로 해석할 수 있음

4.2.3 Word2Vec
원-핫 인코딩의 경우 구현은 간단하지만 챗봇의 경우 많은 단어를 처리하면서 단어 간 유사도를 계산할 수 있어야 좋은 성능을 낼 수 있기 때문에 좋은 선택은 아님
->분산 형태의 단어 임베딩 모델을 사용할 것
신경망 기반 단어 임베딩의 대표적인 방법인 Word2Vec모델을 알아보겠음
Word2Vec은 2013년 구글에서 발표했으며 가장 많이 사용하고 있는 단어 임베딩 모델
기존 신경망 기반의 단어 임베딩 모델에 비해 구조상 차이는 크게 없지만 계산량을 획기적으로 줄여 빠른 학습이 가능
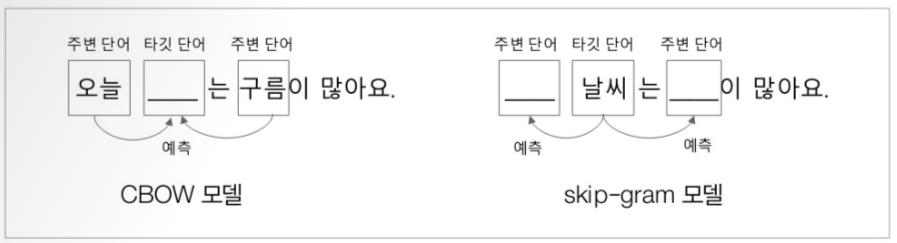
모델 : CBOW, skip-gram
CBOW모델은 맥락이라 표현되는 주변 단어들을 이용해 타깃 단어를 예측하는 신경망 모델
신경망의 입력을 주변 단어들로 구성하고 출력을 타깃 단어로 설정해 학습된 가중치 데이터를 임베딩 벡터로 사용
->타깃 단어의 손실만 계산하면 되기 때문에 학습속도가 빠름
skip-gram모델은 하나의 타깃 단어를 이용해 주변 단어들을 예측하는 신경망 모델
CBOW모델에 비해 예측홰야하는 맥락이 많아짐
->단어 분산 표현력이 우수해 CBOW모델에 비해 임베딩 품질이 우수
Word2Vec의 단어 임베딩은 해당 단어를 밀집 벡터로 표현하며 학습을 통해 의미상 미슷한 단어들을 비슷한 벡터공간에 위치시킴
벡터 특성상 의미에 따라 방향성을 갖게 됨
임베딩된 벡터들 간 연산이 가능하기 때문에 단어 간 관계를 계산할 수 있음
Word2vec 모델을 텐서플로나 케라스 같은 신경망 라이브러리를 이용해 직접 구현할 수도 있지만 오픈소스 라이브러리가 이미 존재하며, 이 책에서는 토픽 모델링과 자연어 처리를 위한 라이브러리인 Gensim패키지를 사용
한국어 Word2Vec을 만들기 위해서는 한국어 말뭉치를 수집해야함
웹에서는 한국어 위키나 네이버 영화 리뷰 데이터를 제외하곤 한국어 말뭉치를 구하기 쉽지 않음
네이버 영화 리뷰 데이터를 이용해 모델을 만들어 보겠음
말뭉치 데이터는 양이 많기 때문에 모델을 학습하는데 시간이 다소 걸림
Word2Vec을 사용할 때마다 오랜 시간이 걸리는 모델 학습을 매번 할 수 없으므로 각 단어의 임베딩 벡터가 설정되어 있는 모델을 파일로 저장
from gensim.models import Word2Vec from konlpy.tag import Komoran import time #네이버 영화 리뷰 데이터 읽어오기 def read_review_data(filename): with open(filename, 'r') as f: data=[line.split['\t'] for line in f.read().splitlines()] data=data[1:] return data #학습 시간 측정 시작 start=time.time() #리뷰 파일 읽어오기 print('1) 말뭉치 데이터 읽기 시작') review_data=read_review_data('./ratings.txt') print(len(review_data)) #전체 데이터 개수 print('1) 말뭉치 데이터 읽기 완료 : ',time.time()-start) #문장 단위로 명사만 추출해 학습 입력 데이터로 만듦 print('2)형태소에서 명사만 추출 시작') komoran=Komoran() docs=[komoran.nouns(sentence[1]) for sentence in review_data] print('2) 형태소에서 명사만 추출 완료 : ',time.time()-start) #Word2Vec 모델 학습 print('3) Word2Vec 모델 학습 시작') model=Word2Vec(sentences=docs, size=200, window=4, hs=1, min_count=2, sg=1) ''' sentences : Word2Vec 모델 학습에 필요한 문장 데이터, 모델의 입력값 size : 단어 임베딩 벡터의 차원(크기) window : 주변 단어 윈도우의 크기 hs : 0(0이 아닌 경우 음수 샘플링 사용), 1(모델 학습에 softmax사용) min_count : 단어 최소 빈도 수 제한(설정된 min_count 빈도 수 이하의 단어들은 학습하지 않음) sg:0(CBOW모덿), 1(skip-gram모델) ''' print('3) Word2Vec 모델 학습 완료 :',time.time()-start) #모델 저장 print('4) 학습된 모델 저장 시작') model.save('nvmc,.model') print('4) 학습된 모델 저장 완료 : ',time.time()-start) #학습된 말뭉치 수, 코퍼스 내 전체 단어 수 print('corpus_count : ',model.corpus_count) print('corpus_total_words : ',model.corpus_total_words)from gensim.models import Word2Vec # 모델 로딩 model=Word2Vec.load('nvmc.model') print('corpus_total_words : ', model_corpus_total_words) # '사랑'이란 단어로 생성한 단어 임베딩 벡터 print('사랑 : ',model.wv['사랑']) # 단어 유사도 계산 print('일요일=월요일\t',model.wv.similarity(w1='일요일',w2='월요일')) print('안성기=배우\t',model.wv.similarity(w1='안성기',w2='배우')) print('대기업=삼성\t',model.wv.similarity(w1='대기업',w2='삼성')) print('일요일!=삼성\t',model.wv.similarity(w1='일요일',w2='삼성')) print('히어로!=삼성\t',model.wv.similarity(w1='일요일',w2='월요일')) # 가장 유사한 단어 추출 print(model.wv.most_similar('안성기',topn=5)) print(model.wv.most_similar('시리즈',topn=5))4.3 마치며
컴퓨터는 자연어를 있는 그대로 처리할 수 없으므로 연산 가능한 형태로 변환해야함
자연어를 컴퓨터 연산에 효율적인 벡터 형태로 변환하는 과정을 거치는데 이를 임베딩이라함
말뭉치의 품질과 데이터 양이 충분하다면 훌륭한 품질의 임베딩 모델을 구축가능
임베딩은 사람이 이해하는 정보를 컴퓨터가 이해할 수 있는 형태로 변환해주는 역할을 하기 때문에 일반적으로 신경망 모델의 입력으로 많이 사용됨
'공부 > 처음 배우는 딥러닝 챗봇' 카테고리의 다른 글
chapter6. 챗봇 엔진에 필요한 딥러닝 모델 (0) 2023.05.08 chapter5. 텍스트 유사도 (0) 2023.04.13 chapter3.토크나이징 (0) 2023.04.13 - 문장 임베딩은 문장 전체를 벡터로 표현하는 방법