-
8~9주차-Image-to-Image Translation with Conditional Adversarial Networks교육/가짜연구소-반고흐전시전 2021. 9. 15. 11:04728x90
https://arxiv.org/abs/1611.07004
Image-to-Image Translation with Conditional Adversarial Networks
We investigate conditional adversarial networks as a general-purpose solution to image-to-image translation problems. These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping. This mak
arxiv.org
Image-to-Image Translation with Conditional Adversarial Networks
Abstract
GAN이 입력 이미지에서 출력 이미지로 매핑하는 것뿐만 아니라 매핑 손실함수도 함께 학습
->label map으로부터 사진 합성, edge map으로부터 개체 재구성, 이미지의 색채화에 효과적이라는 걸 증명
1.Introduction
여태까지 task들은pixel로부터 pixel을 예측하는 같은 작업을 하는 것임에도 불구하고 특수한 목적을 가진 machinery로 분리되어 처리되었음->공통적인 framework 개발이 목적
CNN이 이미지 예측에 유용하게 쓰이지만 여전히 수동으로 조정해줘야하는 것들이 있음(손실함수)
naive 접근 방식을 취하고 예측 픽셀과 실제 실제 픽셀 간의 유클리드 거리를 최소화하도록하면 blurry한 결과가 생성되는 경향이 있음 why?모든 가능한 출력을 평균화함으로써 유클리드 거리가 최소화되기 때문
->GAN이 blurry한 결과를 개선하여 output과 real image를 indistinguishable하게 했음
이 논문에서는 conditional setting한 GAN을 사용하여 이미지 변환
정리하자면 이전 논문들은 특정 응용 프로그램에 중점을 둬서 범용적으로 사용불가능했음 다양한 문제에서 conditional GAN이 합리적인 결과를 생성한다는 것을 입증하는 것이 목표!
2. Related work
structured loss for image modeling
이미지 변환문제는 pixel별 분류 또는 회귀로 공식화
->입력 이미지로부터 독립적으로 각각의 출력 픽셀들이 고려되어지고 출력 공간을 구조화되지 않은 걸로 다룸
대신 conditional GAN은 구조화된 손실함수를 학습
구조화된 손실함수는 출력의 joint configuration에 패널티를 줌
Conditional GANs
이전의 몇몇 논문들도 GAN을 적용하긴 했지만 unconditionally하게 적용하거나 term(ex.L2 regression)에 의존하여 출력을 입력에 따라 조건화하고 특정 응용 프로그램에 맞게 조정되었었음
generator와 discriminator도 차이점이 있는데 여기선 generator에 U-Net을 discriminator에선 convolutional PatchGAN classifier를 사용
3. Method
GAN은 랜덤 노이즈 벡터 z로부터 출력 이미지 y로의 mapping을 학습하는 생성 모델
conditional GAN은 관찰된 이미지 x와 랜덤 노이즈 벡터 z에서 y로의 mapping을 학습
3.1. Objective

conditional GAN의 목표 G(Generator)는 목표를 최소화하려하고 D(Discriminator)는 목표를 최대화하는 방향으로 학습

conditioning Discriminator의 중요성테스트를 위해 x를 관찰하지 않는 unconditional variant와 비교 이전 접근에서 traditional loss를 섞는 것이 효과적인 것을 발견, L1 distance가 L2 distance보다 blurr를 덜 유발

final objective 랜덤 노이즈 벡터 z없이도 관찰된 이미지 x로부터 출력 이미지 y로의 mapping을 학습할 수는 있지만 deterministic output을 생산하므로 델타 함수 이외의 분포와 일치하지 않음
더보기deterministcie output?
예측한 그대로 동작하는 알고리즘이다. 어떤 특정한 입력이 들어오면 언제나 똑같은 과정을 거쳐서 언제나 똑같은 결과
delta function 분포?
과거의 conditional GAN은 이를 인정하고 x외의 gaussian noise z를 generator에 대한 입력으로 제공했지만 generator는 noise를 무시하도록 학습하는 것을 발견->효과 X
최종 모델에서 train과 test에 generator의 여러 레이어에 적용된 dropout형태의 noise만 제공
dropout noise에도 불구하고 네트워크 출력에서 아주 작은 확률만 관찰
높은 확률적인 출력을 생산해내는 conditional GAN을 설계하는 것은 모델링한 조건부 분포의 전체 엔트로피를 포착하므로 중요
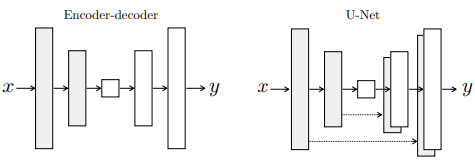
U-Net을 이용하면 초반부의 정보도 전달 가능 3.2. Network architectures
A. Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. In ICLR, 2016 의 generator와 discriminator 아키텍처를 적용
둘 다 convolution-BatchNorm-ReLU 모듈 사용
https://arxiv.org/abs/1511.06434
3.2.1. Generator with skips
'교육 > 가짜연구소-반고흐전시전' 카테고리의 다른 글
10주차-TensorFlow Tutorial(Pix2Pix) (0) 2021.09.15 7주차-TensorFlow Tutorial(DCGAN) (0) 2021.09.15 4~6주차-NIPS 2016 Tutorial: Generative Adversarial Networks: Ian Goodfellow (0) 2021.09.15 3주차-TensorFlow Tutorial(Neural Style Transfer) (0) 2021.09.15 2주차-A Neural Algorithm of Artistic Style (Leon A. Gatys) (0) 2021.08.27