-
[10주차 - Day4] RNN(Recurrent Neural Network)교육/프로그래머스 인공지능 데브코스 2021. 8. 1. 23:19728x90
Deep Learning: 신경망의 기초 - 순환 신경망
시간성(time series)데이터? 특징이 순서를 가지므로 순차 데이터(sequential data)라 부름, 동적이며 가변 길이(variable-length input) ex)심전도 신호, 음성 신호, 주식, 문장, 유전자 배열 등
지금까지 다룬 데이터는 어느 한 순간에 취득한 정적인 데이터이고 고정적인 길이(fixed input) ex)이미지
순환신경망(Recurrent Neural Networks, RNN)와 LSTM
시간성 정보를 활용하여 순차 데이터를 처리하는 효과적인 학습 모델
순서에서 발생되는 서로의 연관성이 순환 신경망을 적절히 잡혀야함=장기 의존성(long-term dependency)
LSTM은 장기 의존성을 잘 다룸, 선별 기억 능력을 가지기 때문
1. 순차 데이터
1.1. 순차 데이터의 표현

대표적인 순차 데이터 : 문자열!
문자열을 일정 단위로 잘라서 정량화(벡터화, 토큰화)시켜야 학습을 시킬 수 있음
->사전(dictionary or term)을 사용하여 표현
사전 구축 방법? 사람이 사용하는 단어를 모아 구축하거나 주어진 말뭉치를 분석하여 단어를 자동추출하여 구축
- 단어가방(BoW(bag of words))
- 단어 각각의 빈도수를 세어 m차원의 벡터로 표현

- 한계 : 정보 검색이나 단순 문서 비교에는 주로 사용되지만 기계 학습에는 부적절
- why? 순서가 없어져서 같은 특징 벡터로 표현되므로 시간성 정보가 사라짐, 문자열은 순서가 중요한데 이렇게 되면 문장의 의미가 완전히 바뀔 수 있음
- ex)April is the cruelest month나 the cruelest month is April나 단어 가방은 같은 특징 벡터로 표현
- 단어 각각의 빈도수를 세어 m차원의 벡터로 표현
- 원핫 코드(one-hot code)
- 각각의 단어가 고유한 벡터의 축을 갖게끔 해당 단어의 위치만 1로 표시
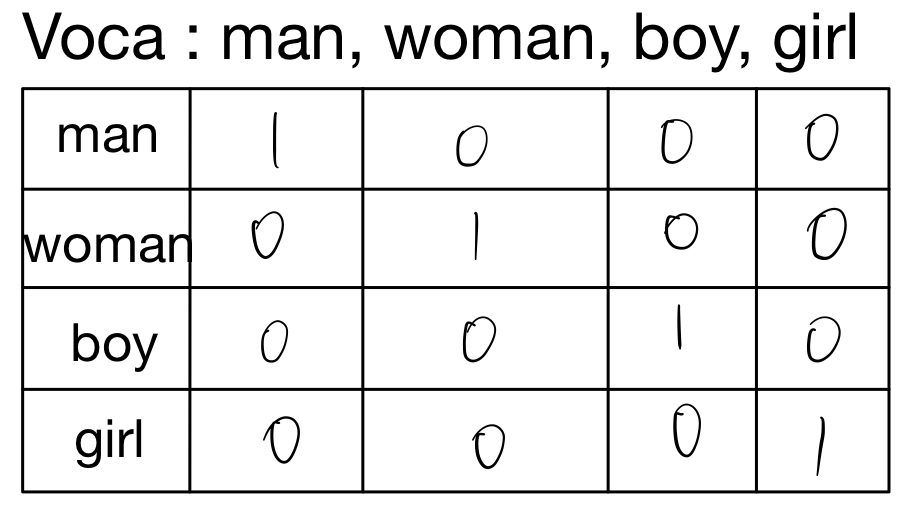
- ex)April is the cruelest month는 x=((0,0,1,0,0,0,...)^T,(0,0,0,0,1,0,...)^T,...)^T로 표현 즉, m차원 벡터를 요소로 가진 5차원 벡터로 표현됨
- 한계 : 한 단어를 표현하는 데 m차원 벡터를 사용하는 비효율 + 단어 간의 유사성을 측정할 수 없음
- 각각의 단어가 고유한 벡터의 축을 갖게끔 해당 단어의 위치만 1로 표시
- 단어 임베딩(word embedding)
- 단어 사이의 상호작용을 분석하여 새로운 공간으로 변환(보통 m보다 훨씬 낮은 차원으로 변환)
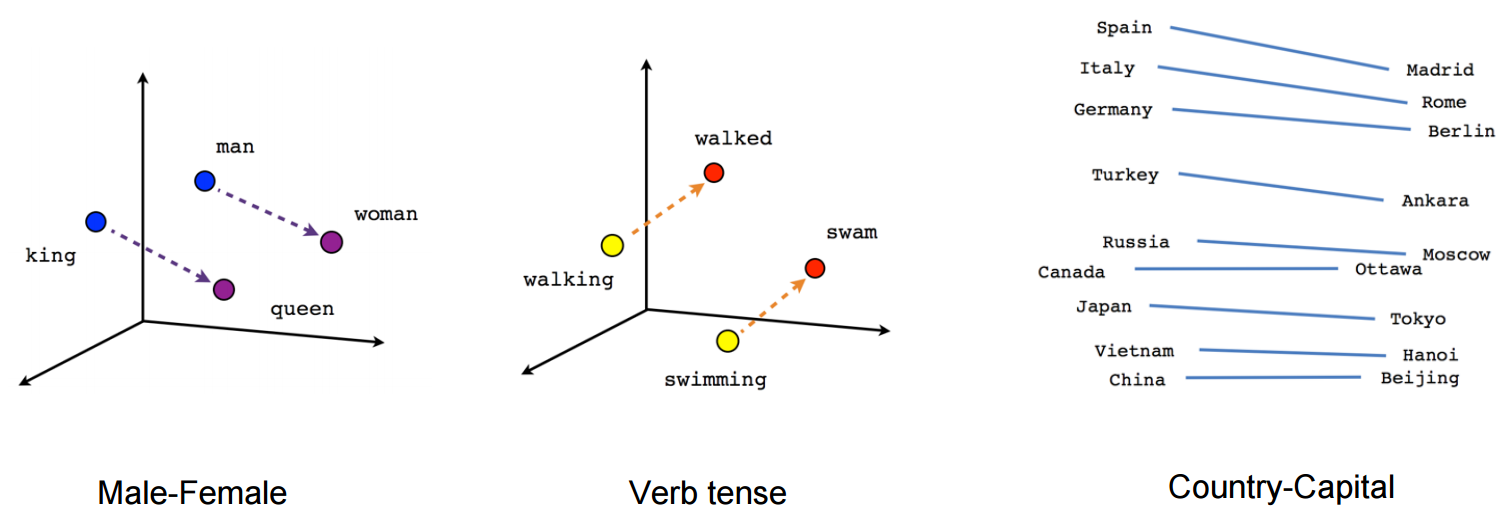
- 단어 사이의 상호작용을 분석하여 새로운 공간으로 변환(보통 m보다 훨씬 낮은 차원으로 변환)
1.2. 순차 데이터의 특성
- 특징이 나타나는 순서가 중요
- ex)아버지가 방에 들어가신다/아버지 가방에 들어가신다
- 샘플마다 길이가 다름->순환 신경망은 은닉층에 순환 연결을 부여하여 가변 길이 수용
- 문맥 의존성
- 비순차 데이터는 공분산이 특징 사이의 의존성을 나타냄
- 순차 데이터는 공분산은 의미가 없고 문맥 의존성이 중요함
- ex)'그녀는 점심때가 다 되어서야 어쩌구 저쩌구 점심을 먹었는데, 철수는 어쩌구 저쩌구'라는 문장이 있으면, '그녀는'이랑 '먹었는데'가 강한 문맥 의존성을 가짐, 중간에 어쩌구 저쩌구들은 다 필요없음 근데 둘 사이의 간격이 어쩌구 저쩌구 때문에 크므로 장기 의존성이라고 부름->LSTM으로 처리
2. 순환 신경망(RNN, Recurrent Neural Network)
순환 신경망(RNN)이 갖추어야할 세 가지 필수 기능
- 시간성 : 특징을 순서대로 한 번에 하나씩 입력
- 가변 길이 : 길이가 T인 샘플을 처리하려면 은닉층이 T번 나타나야함(T는 가변적)
- 문맥 의존성 : 이전 특징을 기억하고 있다가 적절한 순간에 활용해야함
2.1. 구조
공통점 : 입력층, 은닉층, 출력층을 가짐
차이점 : 은닉층이 순환 연결(recurrent edge(=connection))을 가짐
->시간성, 가변 길이, 문맥 의존성을 모두 처리할 수 있음, t-1순간에 발생한 정보를 t순간으로 전달하는 역할
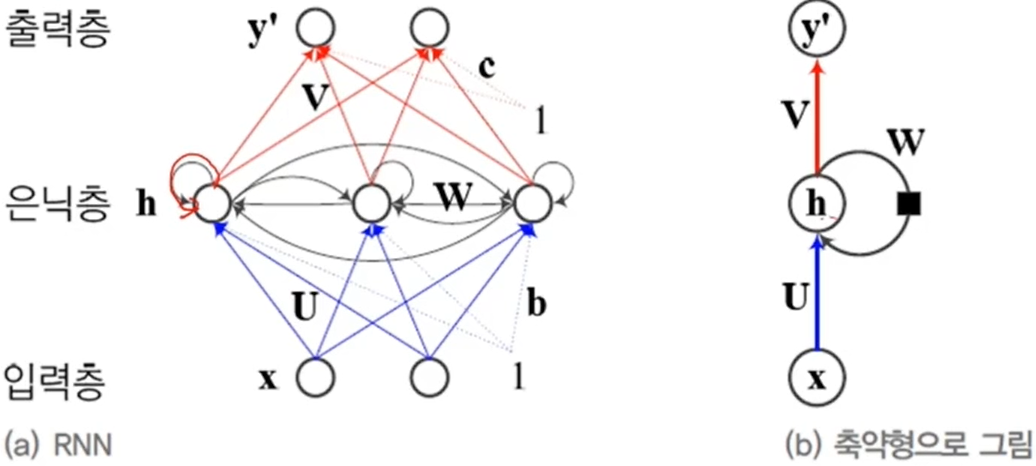
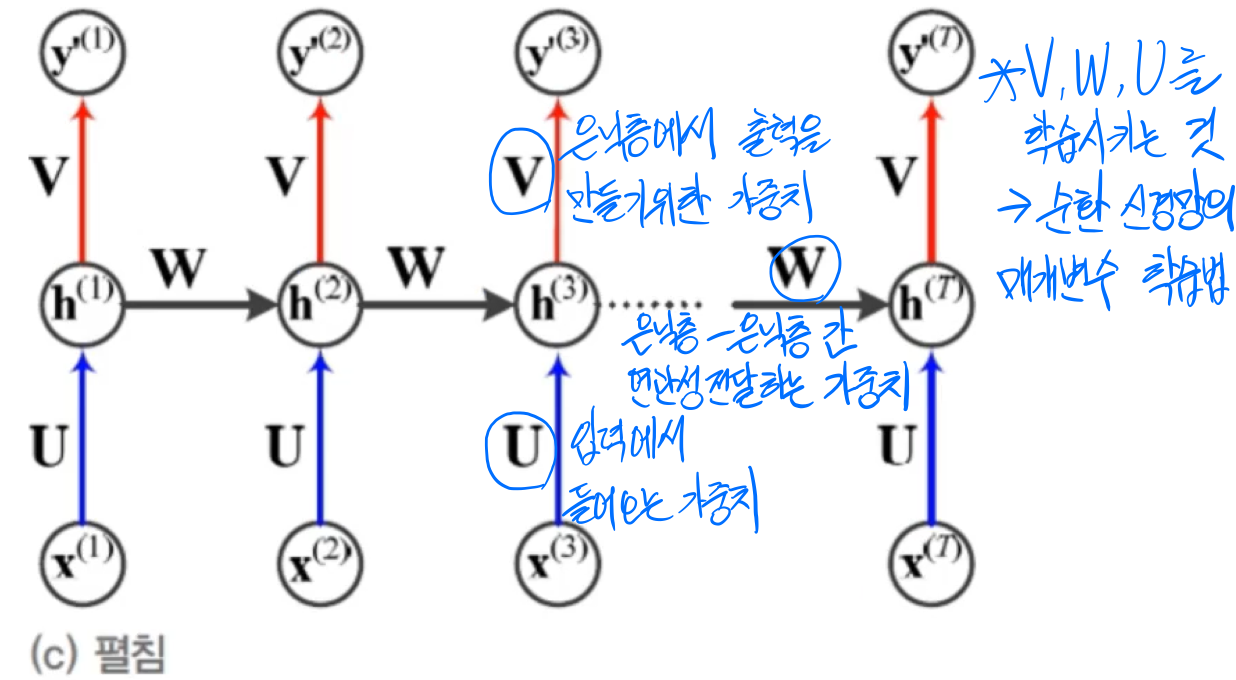

RNN을 수식으로 정리 순환 신경망의 매개변수(가중치 집합)은 θ={U,W,V,b,c}
- U : 입력층과 은닉층을 연결하는 p*d행렬
- W : 은닉층과 은닉층을 연결하는 p*p행렬
- V : 은닉층과 출력층을 연결하는 q*p행렬
- b,c : 바이어스, p*1행렬, q*1행렬
->RNN학습은 훈련집합을 최적의 성능으로 예측하는 θ값을 찾는 일
위에서 RNN을 설명한 그림을 잘 살펴보면 매개변수 U, W, V가 어느 순간이건 U, W, V로 동일한 것을 알 수 있음(U1, U2, 이런 식이 아니라 U 1개라는 말)
->매 순간 다른 값을 사용하지 않고 같은 값을 공유하는 매개변수 공유(≒CNN의 weight sharing)
매개변수 공유의 장점
- 매개변수 수가 획기적으로 줄어듦
- 매개변수의 수가 특징 벡터의 길이 T에 무관
- 특징이 나타나는 순간이 바뀌어도 같거나 유사한 출력을 만들 수 있음

기본적인 RNN 그래프(W=θ) 입력의 개수 T=출력의 개수 L 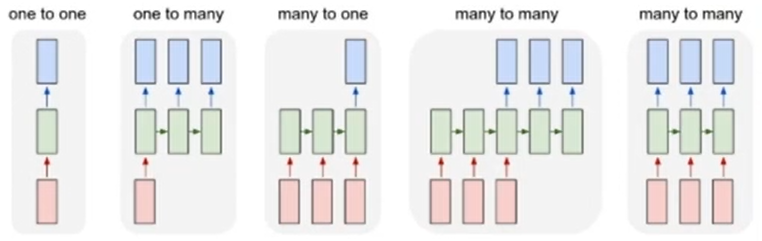
다양한 RNN구조 *문장 대 문장(sequence to sequence) RNN의 연산 그래프 : many to one(encoder), one to many(decoder)
->transformer구조 : 들어오는 정보를 중간 매개값으로 바꾸고 그걸 변환해서 출력해주는 구조, representation
2.2. 동작

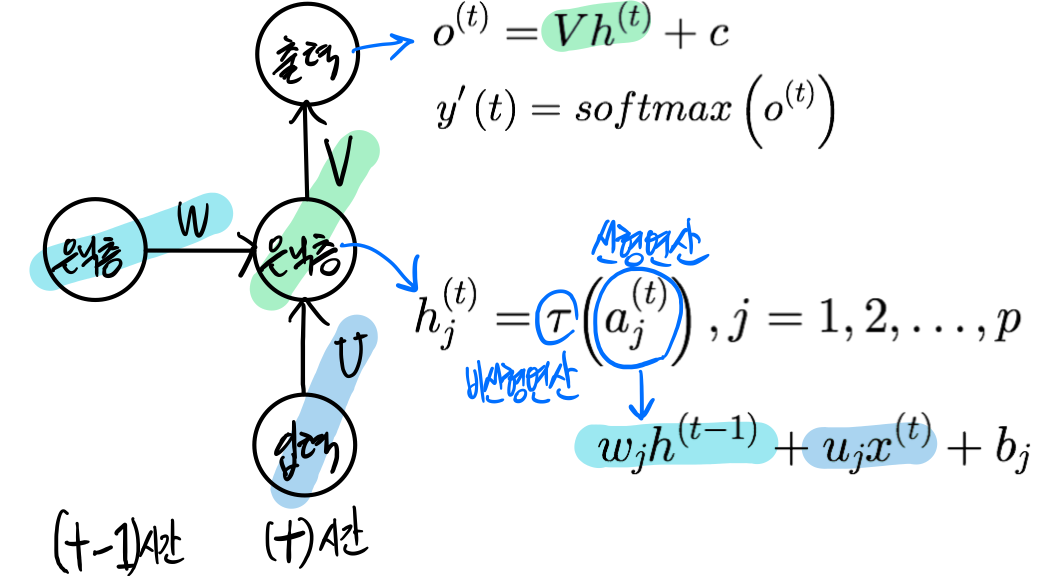
RNN의 기억(memory)과 문맥 의존성 기능
- 기억 : 상태 h(t)가 바뀌면 출력 y'(t)가 바뀜
- 문맥 의존성 : x(t)와 상호작용을 한다고 볼 수 있음
2.3. BPTT(BackPropagation Through Time)학습
- RNN과 DMLP의 공통점 : 입력층, 은닉층, 출력층을 가짐
- RNN과 DMLP의 차이점
- RNN :
- 샘플마다 은닉층의 수가 다름(얼마나 전달될 수 있는지에 따라 은닉층의 수가 다름)
- 매순간 입력과 출력이 있음
- 가중치 공유(W)
- DMLP
- 왼쪽에 입력, 오른쪽에 출력이 있음
- 가중치가 여러개(w1, w2, w3, ...)
- RNN :
목적함수의 정의 : 예측 출력값은 y', 목표값은 y로 표기하고 평균제곱오차, 교차 엔트로피, 로그우도 중에 선택하여 사용

경사도 계산

경사도 계산하는 방법이라는데 사실 뭐라는지 모루겠움^p^ BPTT(Back-Propagation Through Time)알고리즘
vji로 미분하는 식을 행렬 전체를 위한 식으로 확장하고 가중치 모두를 유도하면 BPTT가 완성

모,,,그렇다고 합니다
2.4. 양방향 RNN
왼쪽에서 오른쪽으로만 정보가 흐르는 단방향 RNN은 한계가 존재

->양방향 RNN(Bidirectional RNN) : t순간의 단어는 앞쪽 단어와 뒤쪽 단어 정보를 모두 보고 처리
3. 장기 문맥 의존성(long-term dependency)
관련된 요소가 멀리 떨어진 상황에선 정보가 보존되서 전달되기 어려움
->경사 소멸(gradient vanishing) 또는 경사 폭발(gradient exploding) 문제점이 발생
RNN이 DMLP/CNN보다 심각함
Why? 긴 입력 샘플이 자주 발생하고 가중치 공유 때문에 같은 값을 공유하기 때문에
->LSTM의 등장!
4. LSTM(Long Short Term Memory)
장기/단기 의존성을 저장하면서 효과적으로 관리
4.1. 개폐구(gate)를 이용한 영향력 범위 확장
입력 개폐구와 출력 개폐구
개폐구를 열면 신호가 흐르고 닫으면 차단되는 형태

t:1'길동은' ~~~ t:32'쉬기로' 가 장기문맥의존성으로 연결 LSTM 핵심 요소
- 메모리 블록(셀) : 은닉 상태(hidden state) 장기 기억
- 망각(forget) 개폐구(1:유지, 0:제거) : 기억 유지/제거
- 입력(input) 개폐구 : 입력 연산
- 출력(output) 개폐구 : 출력 연산

RNN과 LSTM의 비교
- RNN : 히든층에 의해 정보가 단순 전달->길어지면 정보의 손실 존재
- LSTM : 메모리 셀로 정보를 전달할지 말지, 입출력을 얼마나 전달할 지를 결정하여 전달->효율적인 정보 관리
4.2. LSTM의 동작

4.3. 망각 개폐구(forget gate)와 작은 구멍(pinhole)
망각 개폐구(forget gate)의 기능 : 이전 순간의 상태(=메모리 블록의 기억)을 지우는 효과

위의 LSTM동작에 추가되는 기능 5. 응용사례
순환 신경망은 분별 모델뿐아니라 생성 모델로도 활용
장기 문맥을 처리하는 데 유리한 LSTM이 주로 사용됨
5.1. 언어모델
NLP(Natural Language Processing)
- NLU : 문자단위, 토큰단위로 처리
- NLG : 문장단위
언어 모델이란 문장, 즉 단어열의 확률분포를 모형화(modeling)
활용 : 음성 인식기, 언어 번역기 등
확률분포를 추정하는 방법
1. n-그램
문장을 n개의 단어씩보면서 확률분포를 예측
차원의 저주때문에 n을 1~3정도로 작게 해야함
2. 다층 퍼셉트론
3. 순환 신경망
현재까지 본 단어열을 기반으로 다음 단어를 예측하는 방식으로 학습
->확률분포 추정뿐만 아니라 문장 생성 기능까지 갖추게 됨
주요언어모델 : ElMo, GPT, BERT 등
5.2. 기계 번역
언어 모델은 입력 문장과 출력 문장의 길이가 같은 데에 비해 기계 번역은 길이가 서로 다른 열 대 열(sequence to sequence)문제, 어순이 다른 문제로 언어모델보다 어려움
->LSTM을 사용하여 번역 과정 전체를 통째로 학습
LSTM을 2개 사용(transformer방식)
- 부호기(encoder, 앞쪽 LSTM) : 원시 언어 무장 x를 h라는 특징 벡터로 변환
- 복호기(decoder, 뒤쪽 LSTM) : h를 가지고 목적 언어 문장 y생성
5.3. 영상 주석 생성
영상 속 물체를 검출하고 인식, 물체의 속성과 행위, 물체 간의 상호작용을 알아내는 일, 의미를 요약하는 문장 생성
과거에는 (물체 분할/인식/단어 생성, 조립) 따로 구현 후 연결->현재는 딥러닝 기술을 사용하여 통째로 학습, CNN으로 영상 분석+LSTM으로 문장 생성
훈련집합 : x는 영상, y는 영상을 기술하는 문장
훈련과정 : 입력 영상 x를 CNN에 입력하여 입력 영상이 어떤 의미인지 벡터차원에 추상화(spatial feature learning)하고 문장 y를 임베딩 공간의 점으로 변환하여 LSTM에 입력하여 문장을 생성(temporal feature learning)
목적함수 : 로그우도를 이용해서 일치 정도(LSTM의 출력과 y가 일치할수록 예측을 잘한다고 평가)를 평가
학습이 최적화해야할 매개변수집합 : CNN매개변수, LSTM매개변수, 단어 임베딩 매개변수->통째로 학습시켜서 한꺼번에 최적화됨
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[11주차 - Day2] DDL, DML, SELECT (0) 2021.08.07 [11주차 - Day1] Redshift 소개 (0) 2021.08.07 [10주차 - Day3] Deep Learning 최적화 (0) 2021.07.28 [10주차 - Day2] CNN Models (0) 2021.07.17 [10주차 - Day1] Deep Learning 기초 (0) 2021.07.07 - 단어가방(BoW(bag of words))