-
0920-모델 선정 중, YOLOR 리뷰프로젝트/catholic 2021. 9. 20. 13:02728x90
사진에 고양이 얼굴만 나오는 게 아니라 몸통만 나오는 경우도 있기 때문에 '고양이'라는 개체를 탐지해야함
object detection으로 고양이를 탐지해서 RoI를 잘라서 데이터셋을 만들 생각
YOLOR보는 중
github : https://github.com/WongKinYiu/yolor
GitHub - WongKinYiu/yolor: implementation of paper - You Only Learn One Representation: Unified Network for Multiple Tasks (http
implementation of paper - You Only Learn One Representation: Unified Network for Multiple Tasks (https://arxiv.org/abs/2105.04206) - GitHub - WongKinYiu/yolor: implementation of paper - You Only Le...
github.com
논문 : https://arxiv.org/pdf/2105.04206v1.pdf
You Only Learn One Representation : Unified Network for Multiple Tasks
Abstract
인간은 명시적 지식(경험)+암시적 지식(무의식)으로 세상을 이해
명시적, 암시적 지식은 암호화되어 뇌에 저장되고 DB로 활용하면 어떤 데이터라도 효과적으로 처리
이 논문은 암시적 지식과 명시적 지식을 함께 인코딩하는 통합 네트워크를 제안
다양한 작업을 동시에 수행하기 위해 통합 표현을 생성
CNN에서 multitask learning, prediction refinement, kernel space alignment를 수행
1. Introduction
인간은 동일한 데이터를 다양한 각도에서도 분석가능/CNN은 단일 목표만 수행가능->다른 유형의 문제에 적용 불가능
why?CNN은 특징만을 추출하고 풍부한 묵지석 지식을 사용하지 않기 때문, 인간의 두뇌는 암시적 지식으로 다양한 작업을 수행하도록 함
암시적 지식이란 잠재의식 상태에서 배운 지식인데 이를 학습하는 방법에 대해 체계적 정의는 없음
일반적으로 명시적/암시적 지식 정의
- neural network에서 shallow layer에서 얻은 지식을 명시적 지식
- deep layer에서 얻은 지식을 암시적 지식
본 논문에서 명시적/암시적 지식 정의
- 관찰을 통해 얻은 지식을 명시적 지식
- 관찰과 상관없이 모델에 내재된 지식을 암시적 지식
본 논문은 명시적 지식과 암시적 지식을 통합한 네트워크를 구축하려고 함
통합 네트워크를 구성하는 방법은 compressive sensing과 deep learning의 결합
extended ditctionary로부터 잔차를 재구성하는 것이 효과적이라는 것을 증명했음
->CNN의 특징 맵을 재구성하기 위해 sparse coding을 사용
- 암시적 지식과 명시적 지식을 통합하여 일반 표현을 학습하고 일반 표현을 통해 다양한 작업을 완료
- 암시적 지식 학습 과정에 kernel space alignment, prediction refinment, multi-task learning을 도입
- 암시적 지식을 모델링하는 도구로 벡터, neural network, 행렬 분해를 사용하는 방법에 대해 논의
- 학습된 암시적 표현이 특정 물리적 특성에 정확히 대응, operator가 목적의 물리적 의미에 부합하면 암시적 지식과 명시적 지식을 통합하는 데 사용할 수 있고 multiplier effect가 있음을 확인
- 객체 감지의 정확도가 높고 속도도 빠름
2. Related work
explicit deep learning+implicit deep learning+knowledge modeling
2.1. Explicit deep learning(명시적 딥러닝)
transformer는 단방향, 쿼리, 키, 값을 사용하여 self-attention을 얻음
더보기attention이전의 seq2seq모델은 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 고정된 크기의 벡터 표현으로 압축하고 디코더는 컨텐스트 벡터를 통해 출력 시퀀스를 만들어내는 형태
seq2seq모델의 단점
1. 고정된 크기의 벡터에 모든 정보를 압축해서 하나에 담으려고 하니 정보 손실 발생
2. RNN의 고질적인 문제 gradient vanishing 존재
그래서 기계 번역 분야에서 입력 문장이 길어지면 번역 품질이 떨어지는 현상이 발생 이를 보정해주기 위한 기법
->attention모델!
attention은 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서 전체 입력 문장을 다시 한번 참고하는데 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중해서 보게 됨
함수로 나타내면 : Attention(Q, K, V) = Attention Value
주어진 쿼리(Query)에 대해 모든 키(Key)와의 유사도를 각각 구하고 키(Key)와 매핑되어있는 각각의 값(Value)에 반영하고 모두 더해서 리턴(리턴한 값=Attention Value)
트랜스포머(Transformer)모델은 seq2seq의 구조인 인코더-디코더를 따르면서 attention만으로 구현한 모델
어텐션을 RNN보정을 위한 용도가 아니라 어텐션으로 인코더와 디코더를 만듦
인코더들->디코더들
여기까지 참고한 링크 : https://wikidocs.net/31379
1) 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인
wikidocs.net
computer vsion에서 self-attention : https://comlini8-8.tistory.com/37
Computer vision 분야에서의 Self-Attention
https://towardsdatascience.com/self-attention-in-computer-vision-2782727021f6 Self-Attention In Computer Vision Using the attention mechanism as the building block in computer vision models towardsd..
comlini8-8.tistory.com
어휴 보다보니 잠와 내일 보긔
non-local network는 시공간에서 pair-wise attention을 추출해내는 방법
입력 데이터에 의해 적절한 커널을 자동으로 선택하는 방법
2.2. Implicit deep learning(암시적 딥러닝)
- implicit neural representation : 다른 작업을 수행하기 위해 이산적인 입력의 매개변수화된 연속 매핑 표현을 얻음
- deep equilibrium model(심층 평형 모델) : implicit learning을 잔차 형태의 신경망으로 변환하고 이에 대한 equilibrium point(평형점) 계산
더보기implicit neural representation
Vincent Sitzmann, Julien Martel, Alexander Bergman, David Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. In Advances in Neural Information Processing Systems (NeurIPS), 2020. 2
deep equilibrium model
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. Deep equilibrium models. In Advances in Neural Information Processing Systems (NeurIPS), 2019. 2
Shaojie Bai, Vladlen Koltun, and J Zico Kolter. Multiscale deep equilibrium models. In Advances in Neural Information Processing Systems (NeurIPS), 2020. 2
Tiancai Wang, Xiangyu Zhang, and Jian Sun. Implicit feature pyramid network for object detection. arXiv preprint arXiv:2012.13563, 2020.
2.3. Knowledge modeling
- sparse representation : 사전 정의된 모형, 사전 정의 또는 학습된 사전을 사용
- memory networks : 다양한 형태의 임베딩을 결합하여 메모리 형성, 메모리 동적 추가, 변경가능
3. How implicit knowledge works?
본 논문의 주된 목적은 암시적 지식을 효과적으로 훈련할 수 있는 통합 네트워크를 구축하는 것
암시적 지식을 훈련하고 이를 빠르게 추론하는 방법에 초점
암시적 표현 zi는 관찰(observation)과 관련이 없으므로 상수 텐서 Z={z1, z2, ..., zk}의 집합으로 생각
3.1. Manifold space reduction
차원을 줄이고 효과적인 작업 달성을 위해 투영 벡터(projection vector)와 암시적 표현(implicit representation)의 내적
3.2. Kernel space alignment
multi-task, multi-head 신경망에서 커널 공간 mislignment는 빈번한 문제
출력 특성(output feature)과 암시적 표현(implicit representation)의 덧셈, 곱셈으로 커널 공간이 신경망의 각 출력 커널 공간을 정렬하도록 변환, 회전, 크기 재조정

3.3. More functions
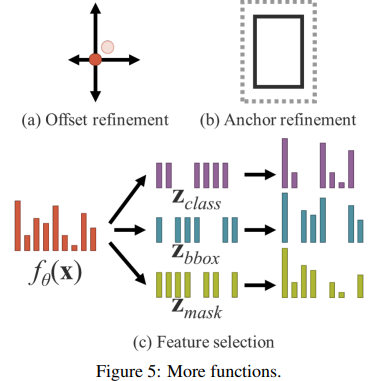
4. Implicit knowledge in our unified networks
기존 네트워크와 통합 네트워크와의 목적 함수 비교+네트워크 훈련에 암시적 지식을 도입하는 것의 중요성 설명
4.1. Formulation of implicit knowledge
Conventional Networks

->동일한 타겟을 가지면 관찰들이 다르더라도 단일점으로 매핑됨(그림 a)
하지만 그림 b처럼 수행되는 것을 바람, 그러기 위해선 오차항 ε를 relax시켜야하는데 이를 위해선 간단한 수학적 방법을 사용하는 것이 불가능하므로 그림 c와 같이 오차항을 모델링해야함

Unified Networks

4.2. Modeling implicit knowledge
- Vector/Matrix/Tensor(=z) : 벡터 z를 암시적 지식의 우선순위로 직접 사용, 암시적 표현으로 직접 사용, 각 차원은 서로 독립적이라고 가정
- Neural Network(=Wz) : 벡터 z를 암시적 지식의 사전으로 사용, 가중치 행렬 W를 사용하여 선형 결합, 비선형화를 수행한 후 암시적 표현이 됨, 각 차원은 서로 종속적이라고 가정
- Matrix Factorization(=Z^T_c) : 암시적 지식의 이전으로 다중 벡터 사용, 다중 벡터 Z와 계수 c는 암시적 표현을 형성
4.3. Training
모델이 처음엔 사전 암시적 지식이 없다고 가정, 즉, 명시적 표현 fθ(x)에 영향을 미치지 않음
결합 연산자 ⁎ ∈ {addition, concatenation}
초기 사전 암시적 z~N(0, σ) 결합연산자 ⁎(multiplication), z~N(1,σ) (σ는 0에 가까운 매우 작은 값)
z와 φ는 훈련 과정에서 역전파 알고리즘으로 훈련됨
4.4. Inference
암시적 지식은 관찰 x와 관련이 없기 때문에 암시적 모델 gφ가 아무리 복잡하더라도 추론 단계가 실행되기 전 상수 텐서로 축소 가능, 즉, 암시적 정보의 형성은 알고리즘의 계산 복잡성에 영향을 거의 미치지 않음

연산자가 곱셈+다음 레이어가 convolutional 레이어면 이걸로 적분 
연산자가 덧셈이고 이전 레이어가 convolutional 레이어이고 활성화 함수가 없는 경우에 이걸로 적분 5. Experiments
MSCOCO 데이터셋으로 실험
5.1. Experimental setup

아래의 3가지 측면에서 암시적 지식을 적용
- feature alignment for FPN
- prediction refinement
- multi-task learning in a single model
(multi-task learning을 다루는 작업에는 객체 탐지, 다중 분류, 특징 임베딩이 포함됨)
YOLOv4-CSP를 기준 모델로 선택하고 그림에서 화살표가 가리키는 위치에
암시적 지식을 도입, 모든 훈련 하이퍼 파라미터는 ScaledYOLOv4 기본세팅
5.2, 5.3, 5.4에 암시적 지식이 도입될 때 다양한 작업에 대한 긍정적인 영향을 확인하기 위해 simplist vector implicit representation과 덧셈 연산자를 사용
5.5에서 명시적 지식과 암시적 지식의 다양한 조합에 대해 다른 연산자를 사용하고 조합의 효율성에 대해 논의
5.6에서 암시적 모델링
5.7에서 암시적 지식을 도입/미도입한 모델을 분석
5.8에서 암시적 지식으로 object detector를 훈련시킨 후 성능 비교
5.2. Feature alignment for FPN
각 FPN의 특징 맵에 암시적 표현을 추가하여 baseline인 YOLOv4-CSP에 비해 AP를 약 0.5%씩 개선(입력이미지는 640*640)
5.3. Prediction refinement for object detection
예측 정제를 위해 YOLO 출력 레이어에 암시적 표현 추가
5.4. Canonical representation for multi-task
동시에 여러 작업을 공유할수있는 모델을 훈련시키려하는 경우 손실 함수에 대해 joint optimization을 실행해야 하므로 실행과정 중에 여러 부분을 끌어와야함 이렇게되면 여러 모델을 개별적으로 훈련시킨 다음 통합하는 것보다 성능나쁨
그래서 멀티태스킹에 대한 표준 훈련(canonical representation for multi-task)을 시킬 것
5.5. Implicit modeling with different operators
명시적 표현과 암시적 표현을 결합하기 위해 다양한 연산자를 사용하여 실험
feature alignment을 위한 암시적 지식에서 덧셈과 concat은 성능 향상되는 반면 곱셈은 성능 저하
prediction refinement를 위한 암시적 지식에서 concat은 출력 차원을 변경하기 때문에 덧셈, 곱셈만 비교했는데 곱셈이 덧셈보다 성능이 좋음->예측할 때 center shift는 덧셈 디코딩을, anchor scale은 곱셈 디코딩을 사용하는데 center 좌표가 그리드로 경계를 이뤄서 영향이 적고 anchor가 더 큰 최적화 공간을 가져서 영향이 큰 것으로 보임

5.6. Modeling implicit knowledge in different ways
벡터, 신경망, 행렬 분해를 포함한 다양한 방식으로 암시적 지식을 모델링시도

5.7. Analysis of implicit models
암시적 지식이 있는 모델의 매개변수, FLOP의 수를 10000분의 1미만으로 늘려서 성능 향상
5.8. Implicit knowledge for object detection

6. Conclusions
이 논문에서 암시적 지식과 명시적 지식을 통합하는 통합 네트워크를 구성하는 방법을 보여주고 단일 모델 아키텍처에서 다중 작업 학습에 여전히 효과적임을 증명
A. Appendix

4가지 종류의 다운샘플링 모듈 사용
- (a)DWT(Discrete Wavelet Transform) : https://github.com/fbcotter/pytorch_wavelets
- (b)ReOrg(Re-Organization) : https://github.com/AlexeyAB/darknet/issues/4662#issuecomment-608886018
- (c)convolution, (d)CSP covolution used in CSPNet : https://github.com/WongKinYiu/CrossStagePartialNetworks/tree/pytorch

(a) : YOLOv4-CSP
(b) : YOLOv4-CSP-fast
(c) : YOLOv4-CSPSSS
(d) : YOLOv4-P6-light, YOLOR-P6, YOLOR-W6
(e) : YOLOR-E6, YOLORD6
(f) : YOLOv4-CSP-SSSS
'프로젝트 > catholic' 카테고리의 다른 글
230307 (0) 2023.03.07 0824-라벨링 (0) 2022.08.24 0917-detect (0) 2021.09.17 0912-unsupervised image segmentation (0) 2021.09.12 0910-Mask R-CNN논문 리뷰 (0) 2021.09.10