-
[16주차 - Day3] Basic Recommendation System 구현 II교육/프로그래머스 인공지능 데브코스 2021. 8. 19. 16:26728x90
ML 기반 추천 엔진 : 협업 필터링 기반 추천 엔진
1. 추천 엔진 아키텍처
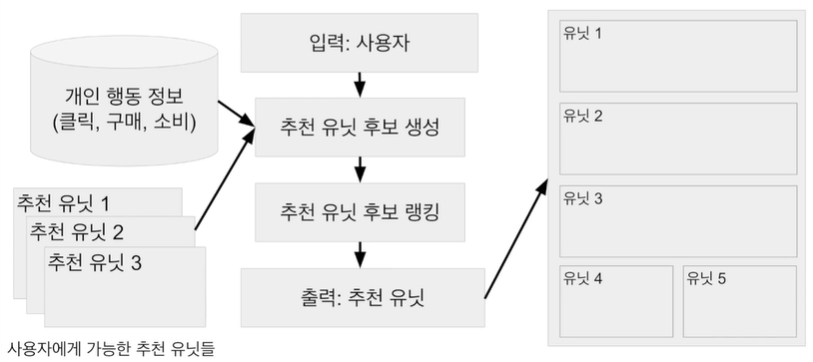
추천엔진의 기본적인 구조(전체 추천 페이지 레벨) 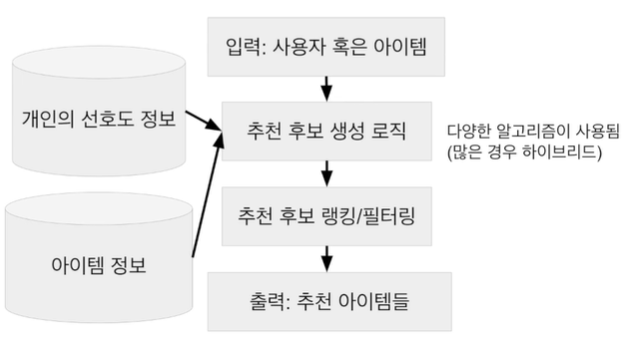
추천엔진의 기본적인 구조(추천 유닛 레벨) 2. 협업 필터링 소개
기본적으로 다른 사용자들의 정보를 이용하여 내 취향을 예측하는 방식
- 사용자 기반(user to user)
- 나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템 추천
- 아이템 기반(item to item)
- 평점의 패턴이 비슷한 아이템들을 찾아서 추천하는 방식
- 예측 모델 기반
- 평점을 예측하는 머신러닝 모델을 만드는 것
구현 방식
- 메모리 기반
- 사용자 기반, 아이템 기반
- 유사도 함수(코사인 유사도, 피어슨 상관계수 유사도, KNN 등)를 사용해 비슷한 사용자,아이템을 추천
- 이해하기 쉽고 설명하기 쉽지만 스케일하기 힘듦(평점 데이터의 부족)
- 모델 기반
- 예측 모델 기반
- 머신러닝을 사용해 비용 함수를 기반으로 학습하여 평점을 예측(PCA, SVD, Matrix Factorization, 딥러닝 등)
- 행렬의 차원을 줄임으로써 평점 데이터 부족 문제를 해결
- 어떻게 동작하는지 설명하기 힘듦(머신러닝이 갖는 일반적인 문제)
협업 필터링(혹은 일반적인 추천 엔진) 평가
- 메모리 기반 협업 필터링
- Top-N(혹은 nDCG)방식으로 평가 : 사용자가 좋아한 아이템을 일부 남겨뒀다가 추천 리스트에 포함되어 있는지 확인하는 방식(추천 순서를 고려해서 평가하면 nDCG(Normalized Discounted Cumulative Gain))
- 모델 기반 협업 필터링
- 머신러닝 알고리즘들이 사용하는 일반적인 방식(ex. RMSE)으로 성능 평가
- Top-N이나 nDCG방식도 사용가능
- 온라인 테스트(AB 테스트)
- 가장 좋은 방식은 실제 사용자에게 노출시키고 성능을 평가하는 것
SurpriseLib
협업 필터링과 관련된 다양한 기능을 제공하는 라이브러리
- KNNBasic객체 이용해서 사용자 기반, 아이템 기반 협업 필터링 구현
- SVD, SVDpp객체 이용해서 모델 기반 협업 필터링 구현
3. 사용자 기반 협업 필터링
1. 사용자들을 벡터(아이템에 대한 평점)로 표현
2. 지정된 사용자와 다른 나머지 사용자들과 공통으로 평점을 준 아이템만 대상으로 유사도 측정
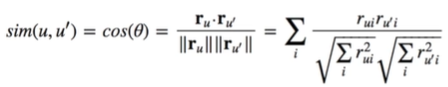
사용자(u)와 다른 사용자 한명(u')씩 비교 3. 가장 비슷한 K명의 사용자를 선택(Top K)하고 K명의 사용자들(u')을 대상으로 사용자(u)가 평가하지 않은 아이템 평가
u'가 평가한 아이템 i의 평점에 u와 u'의 유사도를 가중치로 합을 계산하여 합산한 값이 큰 아이템들을 추천
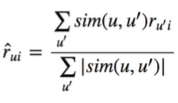

사용자의 유사도 측정 예제 실습
import pandas as pd from sklearn.metrics.pairwise import cosine_similarity dummy_rating = pd.read_csv("https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/dummy_rating.csv", index_col=0) dummy_rating.shape #(5,6) #5명의 사용자, 6개의 아이템dummy_rating.head()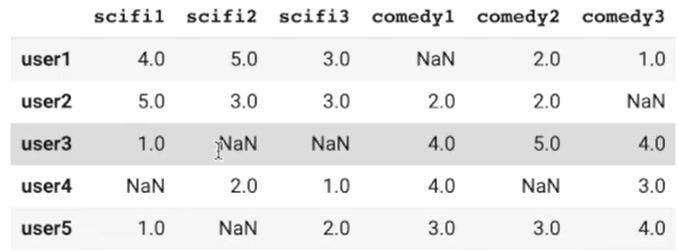
dummy_rating.fillna(0, inplace=True) dummy_rating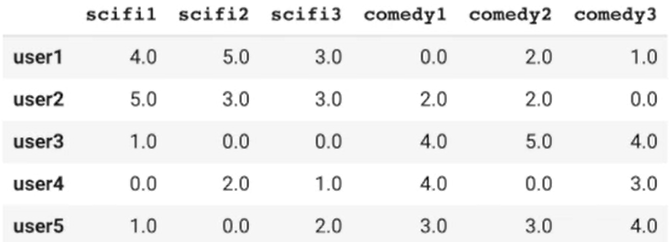
# 평점 정보를 보정. 이후에 코사인 유사도를 사용하면 이는 피어슨 유사도에 해당 def standardize(row): new_row = (row - row.mean())/(row.max()-row.min()) return new_row dummy_rating_std = dummy_rating.apply(standardize) dummy_rating_std.head()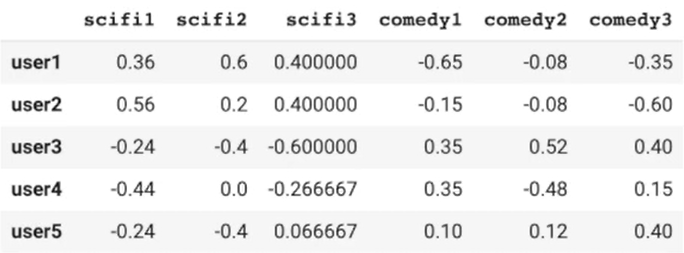
# 정규화 없이 아이템간의 유사도 측정 행렬 만들기 corrMatrix_wo_std = pd.DataFrame(cosine_similarity(dummy_rating), index=dummy_rating.index, columns=dummy_rating.index) corrMatrix_wo_std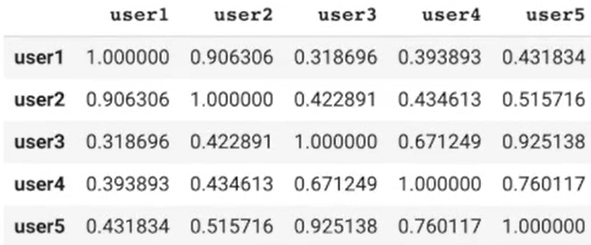
# 정규화 기반 아이템간의 유사도 측정 행렬 만들기 corrMatrix = pd.DataFrame(cosine_similarity(dummy_rating_std), index=dummy_rating.index, columns=dummy_rating.index) corrMatrix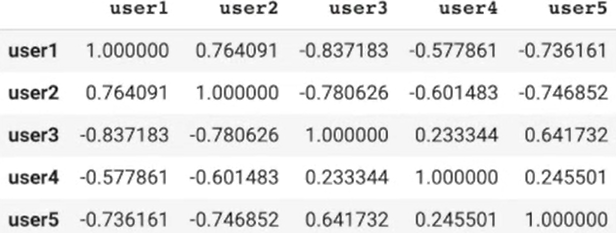
#userId를 입력하면 가장 유사한 평점을 준 user들을 return def get_similar(userId): similar_score = corrMatrix[userId] # 앞서 보정된 값을 가지고 평점의 내림차순으로 정렬 similar_score = similar_score.sort_values(ascending=False) return similar_score scifi_lover = "user1" similar_users = get_similar(scifi_lover) similar_users.head(10)
실습 : 사용자 기반 협업 필터링
1. 라이브러리&데이터 준비
!pip install surprise2. 데이터 로딩
from surprise import Dataset from surprise import Reader from collections import defaultdict import numpy as np import pandas as pd movies = pd.read_csv("https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/movies.csv") ratings = pd.read_csv("https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/ratings.csv")movies.head()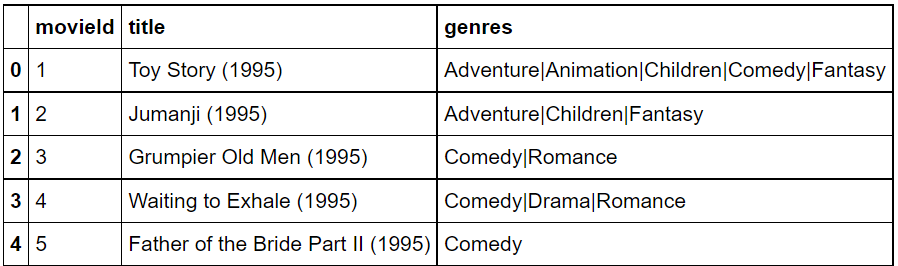
ratings.head()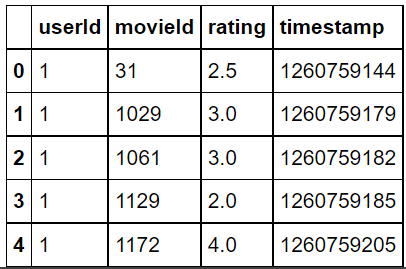
movie_ratings = pd.merge(movies, ratings, left_on='movieId', right_on='movieId') movie_ratings.head()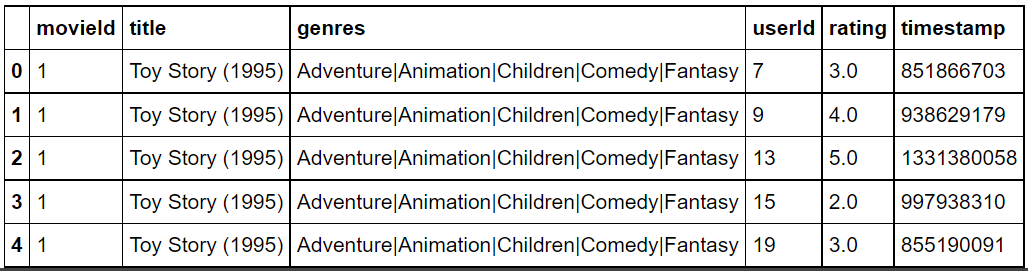
movies.shape #(9125, 3) ratings.shape #(100004,4) movies_ratings.shape #(100004,6)movie_ratings["movieId"].nunique() #9066 #movies를 보면 9125개가 있는데 movie_ratings에는 9066개 있음 #약 60개정도가 ratings가 없는 movie존재했다는 것#영화를 중심으로 평점을 보기 위한 데이터 프레임 생성 movie_rating_summary = movie_ratings[["movieId", "rating"]].groupby(["movieId"]).agg(["count", "median", "mean"]) movie_rating_summary.head()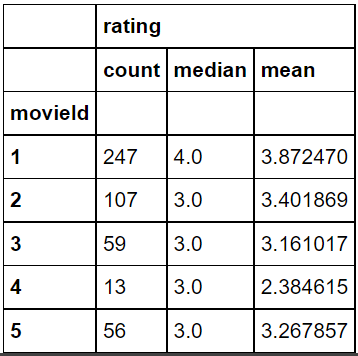
movie_rating_summary.columns #MultiIndex([('ratings','count'),('ratings','median'),('ratings','mean')],) #인덱스 이름이 ratings->count, ratings->median, ratings->mean이런 식으로 멀티 인덱스되어있음 #간단하게 count, meadian, mean으로 바꾸기 movie_rating_summary.columns = ["count", "median", "mean"] movie_rating_summary.columns #Index(['count', 'median', 'mean'], dtype='object')#가장 많은 평점을 받은 영화 Top10 movie_rating_summary.sort_values("count", ascending=False).head(10)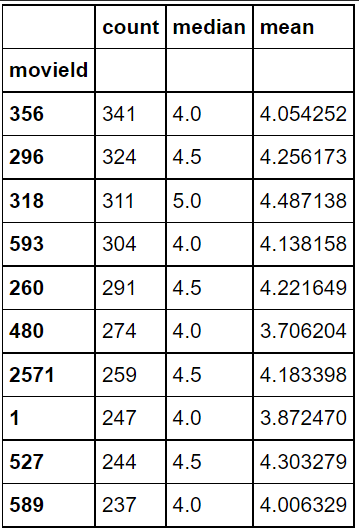
#평점의 평균이 높은 순으로 영화 10개 출력 #but!출력물을 보면 알 수 있겠지만 이렇게하면 평점을 1개만 받았는데 5점이라서 출력되는 결과 발생 movie_rating_summary.sort_values("mean", ascending=False).head(10)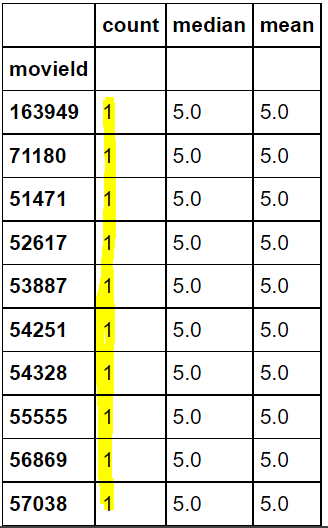
#위의 문제를 해결하기 위해 평점의 갯수가 100개 이상인 영화 중에서 평점 평균이 높은 영화 Top10출력 movie_rating_summary[movie_rating_summary["count"] > 100].sort_values("mean", ascending=False).head(10)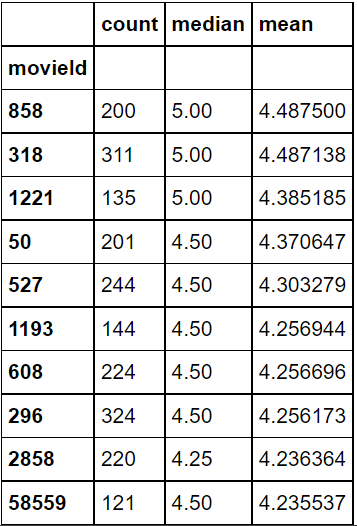
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(16,8)) #movie_ratings_summary의 평균값 sns.distplot(a=movie_rating_summary['mean'], kde=True, color='r')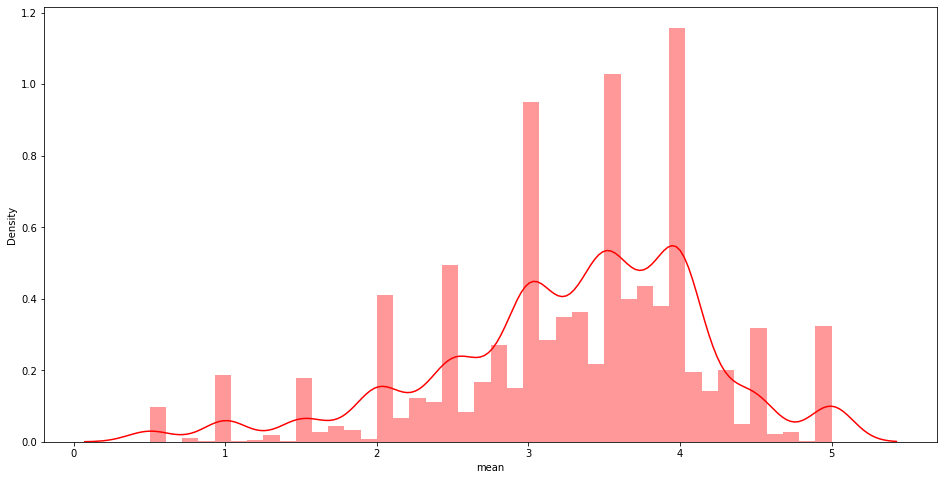
그래프가 약간 오른쪽->사람들이 후하게 평점을 준다 #영화의 평점의 수 count sns.distplot(a=movie_rating_summary['count'], color='g')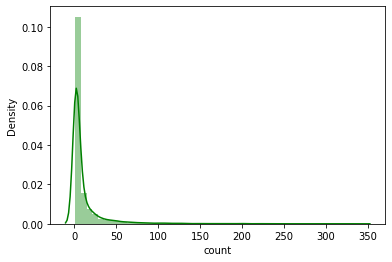
#몇명의 사용자가 있는가? movie_ratings["userId"].nunique() #671 #즉 671명의 사용자가 9066개의 영화에 100004개의 평점을 준 것을 알 수 있음#사용자를 중심으로 평점 정보를 보기 위한 데이터 프레임 생성 user_rating_summary = movie_ratings[["userId", "rating"]].groupby(["userId"]).agg(["count", "median", "mean"]) user_rating_summary.head()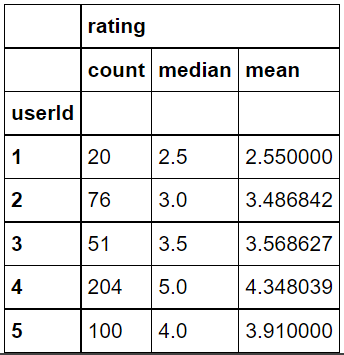
#위에서 멀티인덱스 정리한 것처럼 인덱스 간단하게 정리 user_rating_summary.columns = ["count", "median", "mean"]#가장 많이 평점을 작성한 사용자 Top10 user_rating_summary.sort_values("count", ascending=False).head(10)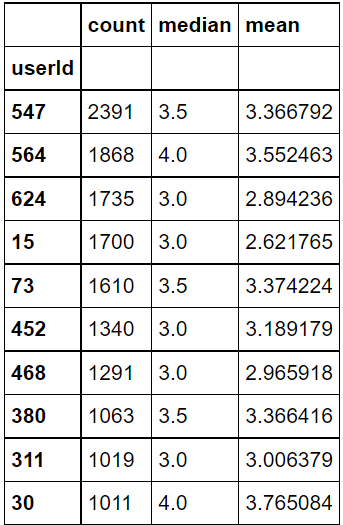
#가장 평점을 후하게 준 사용자 Top10 user_rating_summary.sort_values("median", ascending=False).head(10)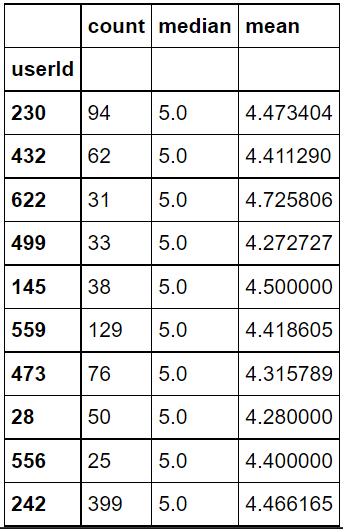
#가장 평점을 짜게 준 사용자 Top10 user_rating_summary.sort_values("median", ascending=True).head(10)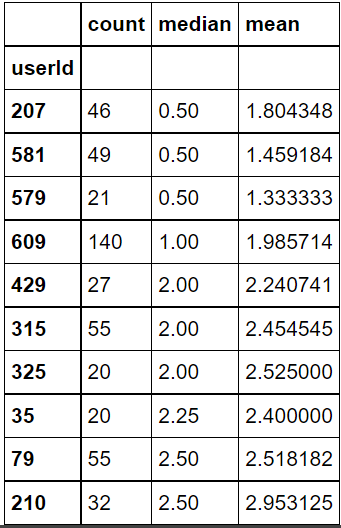
#평점의 평균 분포 sns.distplot(a=user_rating_summary['mean'], kde=True, color='r')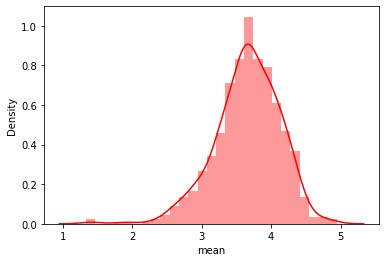
sns.distplot(a=user_rating_summary['count'], kde=True, color='r')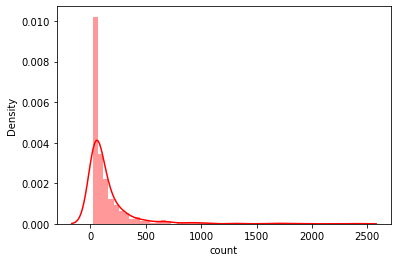
long tail->일부의 사용자들이 많은 수의 평점을 남김 3. 영화 데이터를 surprise 모듈을 통해 로딩
#movieID를 기준으로 영화의 타이틀과 장르 return def getMovieName(movie_ratings, movieID): return movie_ratings[movie_ratings["movieId"] == movieID][["title", "genres"]].values[0] #movie이름을 기준으로 영화의 ID와 장르 return def getMovieID(movie_ratings, movieName): return movie_ratings[movie_ratings["title"] == movieName][["movieId", "genres"]].values[0]!wget "https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/ratings.csv" #파일 포맷(user, item, rating, timestamp(option))4개의 정보가 ,로 구분되고 첫번째 문장은 header라 무시하고 reader객체 생성 reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) #reader객체읽어서 데이터 로딩 data = Dataset.load_from_file("ratings.csv", reader=reader) from surprise import KNNBasic import heapq from collections import defaultdict #build_full_trainset() : train/test set으로 나누지말고 전부 train set으로 trainSet = data.build_full_trainset() #유사도 측정함수의 속성 sim_options = { 'name': 'cosine', #코사인 유사도 'user_based': True #사용자 기반 협업 필터링 } model = KNNBasic(sim_options=sim_options) model.fit(trainSet) simsMatrix = model.compute_similarities()testUser = '85' k = 10 # 주어진 사용자와 가장 흡사한 사용자 N을 찾는다 # 먼저 이를 Surprise 내부 ID로 변환 testUserInnerID = trainSet.to_inner_uid(testUser) print(testUserInnerID) #84 # 이 사용자에 해당하는 레코드를 읽어온다 similarityRow = simsMatrix[testUserInnerID]# users에 모든 사용자들을 일련번호와 유사도를 갖는 튜플의 형태로 저장 # 이 때 본인은 제외 users = [] for innerID, score in enumerate(similarityRow): if (innerID != testUserInnerID): users.append( (innerID, score) ) # 이제 users 리스트에서 유사도 값을 기준으로 가장 큰 k개를 찾는다 kNeighbors = heapq.nlargest(k, users, key=lambda t: t[1]) kNeighbors ''' [(10,1.0), (11,1.0), (13,1.0), (24,1.0), (36,1.0), (44,1.0), (45,1.0), (51,1.0), (53,1.0), (61,1.0)] ''' #(사용자ID, 유사도) #즉, 85번 사용자와 100%일치하는 사용자 10명이 출력된 것# 이제 유사 사용자들을 하나씩 보면서 그들이 평가한 아이템들별로 원 사용자와 유사 사용자간의 유사도를 가중치로 준 평점을 누적한다 # candidates에는 아이템별로 점수를 누적한다. 유사사용자(u')의 평점 * 사용자(u)와 유사 사용자(u')의 유사도 candidates = defaultdict(float) # 이 K명의 최고 유사 사용자를 한명씩 루프를 돌면서 살펴본다 for similarUser in kNeighbors: # similarUser는 앞서 enumerate로 만든 그 포맷임 - (내부ID, 유사도값) innerID = similarUser[0] userSimilarityScore = similarUser[1] # innerID에 해당하는 사용자의 아이템과 평점 정보를 읽어온다. # theirRatings는 (아이템ID, 평점)의 리스트임 theirRatings = trainSet.ur[innerID] # innerID가 평가한 모든 아이템 리스트를 하나씩 보면서 # 아이템ID별로 평점 정보를 합산하되 사용자와의 유사도값을 가중치로 준다 for rating in theirRatings: candidates[rating[0]] += (rating[1]) * userSimilarityScore # 사용자가 이미 평가한 아이템들을 제거할 사전을 만든다 watched = {} for itemID, rating in trainSet.ur[testUserInnerID]: watched[itemID] = 1# 앞서 candidates에서 합산된 스코어를 기준으로 내림차순으로 소팅한 후 # 사용자(u)가 아직 못본 아이템인 경우 추천한다 pos = 0 for itemID, ratingSum in sorted(candidates.items(), key=lambda k: k[1], reverse=True): if not itemID in watched: movieID = trainSet.to_raw_iid(itemID) print(movieID, getMovieName(movie_ratings, int(movieID)), ratingSum) pos += 1 if (pos > 10): break
#앞의 코드를 함수로 만든 것 def recommendForUser(userID): testUserInnerID = trainSet.to_inner_uid(userID) similarityRow = simsMatrix[testUserInnerID] users = [] for innerID, score in enumerate(similarityRow): if (innerID != testUserInnerID): users.append( (innerID, score) ) kNeighbors = heapq.nlargest(k, users, key=lambda t: t[1]) candidates = defaultdict(float) for similarUser in kNeighbors: innerID = similarUser[0] userSimilarityScore = similarUser[1] theirRatings = trainSet.ur[innerID] for rating in theirRatings: candidates[rating[0]] += (rating[1]) * userSimilarityScore watched = {} for itemID, rating in trainSet.ur[testUserInnerID]: watched[itemID] = 1 pos = 0 for itemID, ratingSum in sorted(candidates.items(), key=lambda k: k[1], reverse=True): if not itemID in watched: movieID = trainSet.to_raw_iid(itemID) print(movieID, getMovieName(movie_ratings, int(movieID)), ratingSum) pos += 1 if (pos > 10): break recommendForUser('85')4. 아이템 기반 협업 필터링
주어진 아이템을 기반으로 가장 비슷한 아이템을 찾아서 추천
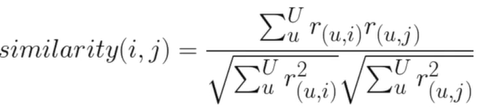
i가 메인 아이템, j가 비교 대상이 되는 아이템 - 분자 : i,j를 모두 평가한 사용자(u)를 대상으로 i와 j간의 유사도를 계산해서 합산
- 분모 : √(모든 사용자(u)의 아이템i 평점을 제곱 후 합산)*√(모든 사용자(u)의 아이템j 평점을 제곱 후 합산)
최종적으로 i와 유사도가 가장 큰 j를 추천(N개)
실습
import pandas as pd from sklearn.metrics.pairwise import cosine_similarity dummy_rating = pd.read_csv("https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/dummy_rating.csv", index_col=0) dummy_rating.head()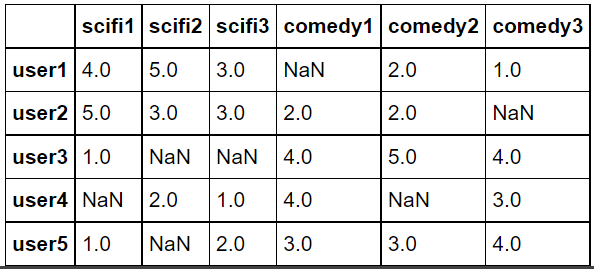
dummy_rating = dummy_rating.T dummy_rating.head()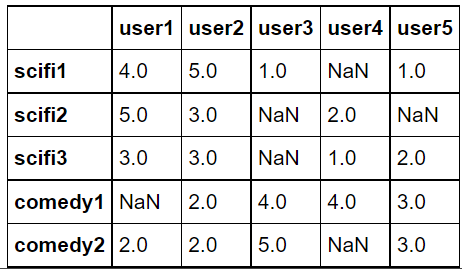
dummy_rating.fillna(0, inplace=True) dummy_rating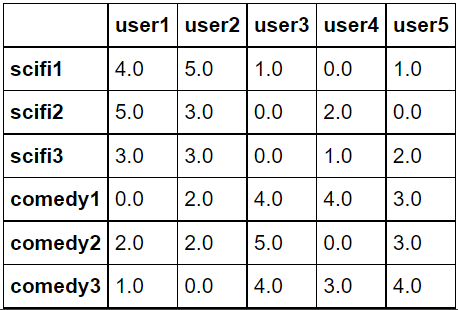
# 평점 정보를 보정. 이후에 코사인 유사도를 사용하면 이는 피어슨 유사도에 해당 def standardize(row): new_row = (row - row.mean())/(row.max()-row.min()) return new_row # 행렬을 transpose해서 데이터 프레임을 생성 dummy_rating_std = dummy_rating.apply(standardize) dummy_rating_std.head()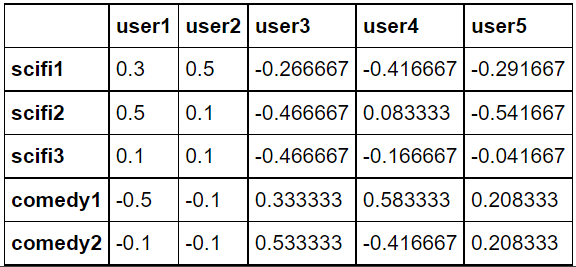
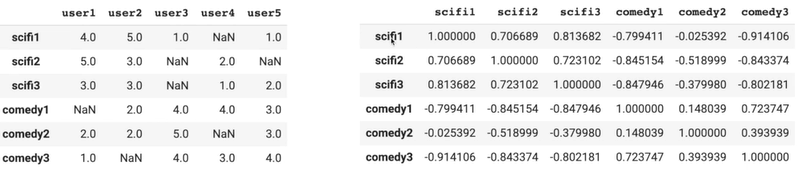
# 아이템간의 유사도 측정 행렬 만들기 corrMatrix = pd.DataFrame(cosine_similarity(dummy_rating_std),index=dummy_rating.index,columns=dummy_rating.index) corrMatrix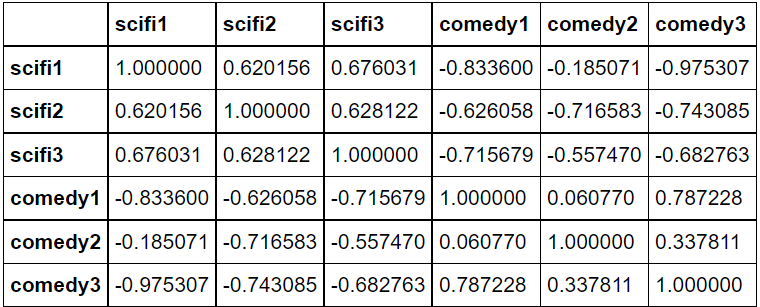
def get_similar(movie_name): # 주어진 영화 이름에 해당하는 유사도 컬럼을 읽어서 평점 정보에 rating를 곱함 similar_score = corrMatrix[movie_name] # 앞서 보정된 값을 가지고 평점의 내림차순으로 정렬 similar_score = similar_score.sort_values(ascending=False) return similar_score movie_i_liked = "scifi1" # 3개의 영화 평점을 가진 사용자를 기반으로 비슷한 아이템을 찾아보자 similar_scores = pd.DataFrame(get_similar(movie_i_liked)) #, ignore_index=True) similar_scores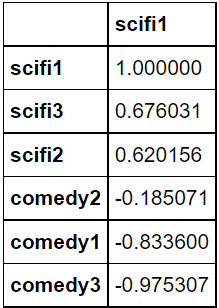
실습 : 아이템 기반 협업 필터링
!pip install surprise !wget "https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/movies.csv" !wget "https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/ratings.csv"1. 데이터 로딩
from surprise import Dataset from surprise import Reader from collections import defaultdict import numpy as np import pandas as pd movies = pd.read_csv("movies.csv") ratings = pd.read_csv("ratings.csv") movies.head()
ratings.head()
movie_ratings = pd.merge(movies, ratings, left_on='movieId', right_on='movieId') movie_ratings.head()
movies.shape #(9125, 3) ratings.shape #(100004,4) movie_ratings.shape #(100004,6)2. 영화 데이터를 surprise 모듈을 통해 로딩
def getMovieName(movie_ratings, movieID): return movie_ratings[movie_ratings["movieId"] == movieID][["title", "genres"]].values[0] def getMovieID(movie_ratings, movieName): return movie_ratings[movie_ratings["title"] == movieName][["movieId", "genres"]].values[0] reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file("ratings.csv", reader=reader) from surprise import KNNBasic import heapq from collections import defaultdict # 데이터를 훈련용과 테스트용으로 나누지 말고 모두 리턴 trainSet = data.build_full_trainset()sim_options = { 'name': 'cosine', 'user_based': False } # 아이템 기반과 코사인 유사도 기반으로 동작하는 모델 생성 model = KNNBasic(sim_options=sim_options) # 데이터로부터 아이템 벡터 생성 model.fit(trainSet) # 아이템간의 유사도 행렬 계산 simsMatrix = model.compute_similarities() ''' Computing the cosine similarity matrix... Done computing similarity matrix. Computing the cosine similarity matrix... Done computing similarity matrix. '''testUserId = '85' k = 10 pd.set_option('display.max_colwidth', -1) display(movie_ratings[movie_ratings["userId"] == int(testUserId)].sort_values("rating", ascending=False))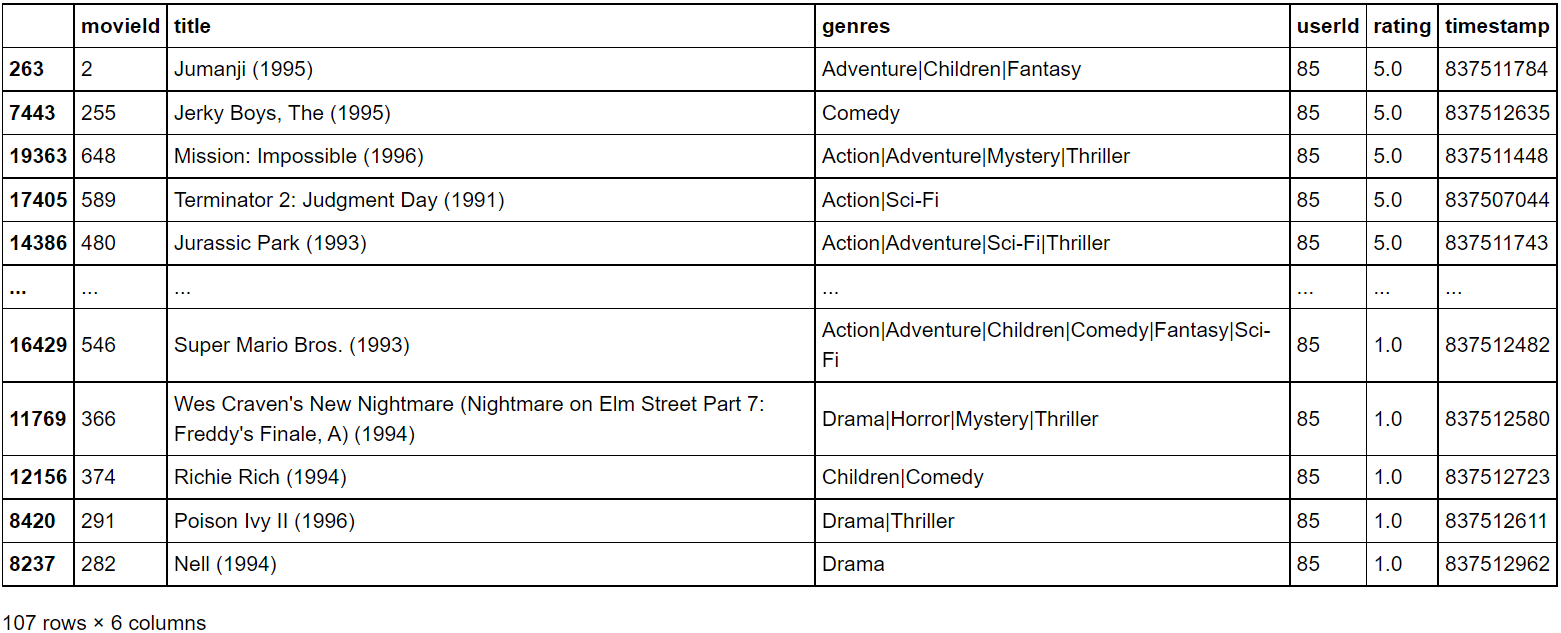
testUserInnerID = trainSet.to_inner_uid(testUserId) # 이 사용자가 좋아한 영화 k개를 읽어서 kNeighbors에 저장 testUserRatings = trainSet.ur[testUserInnerID] kNeighbors = heapq.nlargest(k, testUserRatings, key=lambda t: t[1]) # 이 사용자 좋아한 영화들과 비슷한 영화를 찾아서 candidates에 유사도 가중치를 곱해서 저장 candidates = defaultdict(float) for itemID, rating in kNeighbors: similarityRow = simsMatrix[itemID] for innerID, score in enumerate(similarityRow): candidates[innerID] += score * (rating) # 사용자가 이미 본 아이템들을 기록 watched = {} for itemID, rating in trainSet.ur[testUserInnerID]: watched[itemID] = 1 pos = 0 for itemID, ratingSum in sorted(candidates.items(), key=lambda t: t[1], reverse=True): if not itemID in watched: movieID = trainSet.to_raw_iid(itemID) print(movieID, getMovieName(movie_ratings, int(movieID)), ratingSum) pos += 1 if (pos > 10): break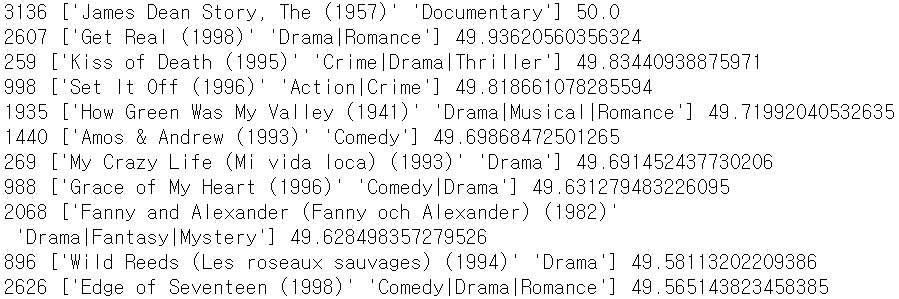
def recommendForItem(userID): testUserInnerID = trainSet.to_inner_uid(userID) testUserRatings = trainSet.ur[testUserInnerID] kNeighbors = heapq.nlargest(k, testUserRatings, key=lambda t: t[1]) candidates = defaultdict(float) for itemID, rating in kNeighbors: similarityRow = simsMatrix[itemID] for innerID, score in enumerate(similarityRow): candidates[innerID] += score * (rating) watched = {} for itemID, rating in trainSet.ur[testUserInnerID]: watched[itemID] = 1 pos = 0 for itemID, ratingSum in sorted(candidates.items(), key=itemgetter(1), reverse=True): if not itemID in watched: movieID = trainSet.to_raw_iid(itemID) print(movieID, getMovieName(movie_ratings, int(movieID)), ratingSum) pos += 1 if (pos > 10): break recommendForItem('85')'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
최종 프로젝트 ~2주차 (0) 2021.09.07 [16주차 - Day4] Deep Learning 기반의 Recommendation System 구현 I (0) 2021.08.20 [16주차 - Day2] Basic Recommendation System 구현 I (0) 2021.08.18 [16주차 - Day1] Recommendation system이란 (0) 2021.08.18 [15주차 - Day2] GAN, Style Transfer (0) 2021.08.11 - 사용자 기반(user to user)