-
[16주차 - Day4] Deep Learning 기반의 Recommendation System 구현 I교육/프로그래머스 인공지능 데브코스 2021. 8. 20. 12:03728x90
ML 기반 추천 엔진 : SVD & 딥러닝 추천엔진
1. SVD알고리즘 소개
사용자/아이템기반(메모리기반) 협업 필터링의 문제점
- 확장성(scalability) : 큰 행렬 계산은 여러모로 쉽지 않음
- 부족한 데이터(sparse data)
->모델 기반 협업 필터링으로 해결
- 머신러닝기술을 사용해 평점을 예측
- 입력은 사용자, 아이템 평점 행렬
- 행렬분해(Matrix Factorization)방식
- 딥러닝 방식
행렬 분해 방식
협업 필터링 문제를 사용자-아이템 평점 행렬을 채우는 문제로 재정의
사용자, 아이템을 적은 수의 차원으로 기술함으로써(차원축소) 문제를 간단화
- PCA(Principal Component Analysis)
- 차원을 축소(Dimensionality Reduction)하되 원래 의미는 최대한 그대로 간직
- 비어있는 칸이 있으면 동작X->굉장히 큰 행렬이라 계산량이 너무 많고 시간이 오래 걸리고 이해하는데 오래걸릴때 사용
- 행렬의 크기는 줄지만 어떤 이유로 줄었는지 이해하기 힘든 문제점이 있음
- SVD(Singular Vector Decomposition)
- 2개 혹은 3개의 작은 행렬의 곱으로 단순화(일종의 소인수 분해)
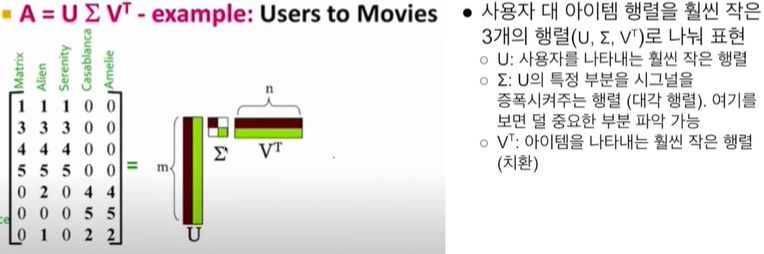
- 비어있는 칸이 있으면 동작X
- 2개 혹은 3개의 작은 행렬의 곱으로 단순화(일종의 소인수 분해)
- SVD++
- SVD나 PCA는 완전하게 채워져있는 행렬의 차원수를 줄이는 방식
- SVD++는 sparse행렬이 주어졌을 때 비어있는 셀들을 채우는 방법을 배우는 알고리즘
- 채워진 셀들의 값을 최대한 비슷하게 채우는 방식으로 학습(에러율(보통 RMSE값) 최소화)
- A(사용자 대 아이템 평점 행렬)를 입력으로 주면 U(사용자 행렬), ∑(스케일 행렬), V^T(아이템 행렬)를 찾아냄
2. SVD기반 추천 엔진 실습
!pip install surprise !wget "https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/movies.csv" !wget "https://grepp-reco-test.s3.ap-northeast-2.amazonaws.com/movielens/ratings.csv"1. 데이터 로딩
import numpy as np import pandas as pd movies=pd.read_csv("movies.csv") ratings=pd.read_csv("ratings.csv")movies.head()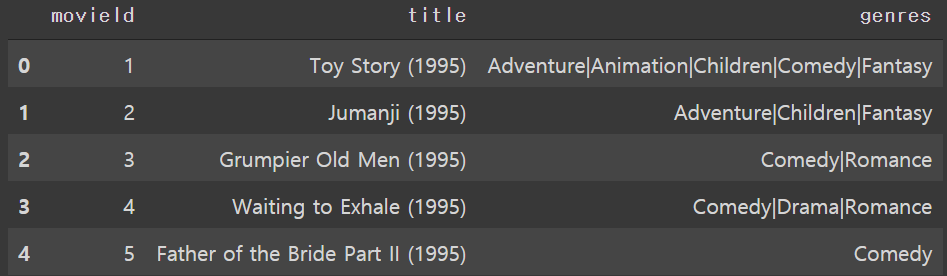
ratings.head()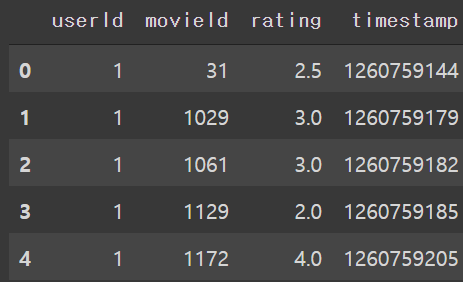
#사용자 대 아이템 행렬은 출력해보면 평점 데이터의 실상을 보여줌->희소행렬,NaN값이 굉장히 많음 #행 userid 열은 movieid 값은 rating itemRatings=ratings.pivot_table(index=['userId'], columns=['movieId'], values='rating') itemRatings.head()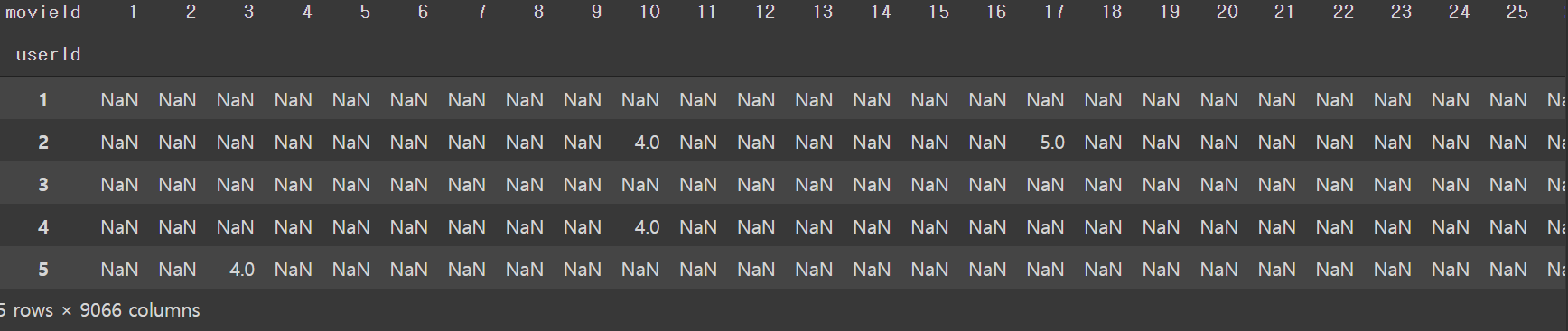
movie_ratings = pd.merge(movies, ratings, left_on='movieId', right_on='movieId') movie_ratings.head()
timestamp가 RNN같은데서 중요한 역할을 함 movies.shape #(9125, 3) ratings.shape #(100004,6) movie_ratings.shape #(100004,6)2. 영화 데이터를 surprise모듈을 통해 로딩
def getMovieName(movie_ratings, movieID): return movie_ratings[movie_ratings["movieId"] == movieID][["title", "genres"]].values[0] def getMovieID(movie_ratings, movieName): return movie_ratings[movie_ratings["title"] == movieName][["movieId", "genres"]].values[0]reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1) data = Dataset.load_from_file("ratings.csv", reader=reader) from surprise import KNNBasic import heapq from collections import defaultdict from surprise import SVD from surprise import NormalPredictor from surprise.model_selection import GridSearchCV #하이퍼 파라미터 그리드 검색을 통해 최적의 파라미터를 찾음 #scikit-learn의 GridSearchCV와 아주 흡사 #n.factors : 축소 차원수(시그마 행렬의 차원수 - r) #n.epochs : 전체 데이터 셋을 훈련시키는 횟수 #lr_all : 학습률 param_grid={ 'n_epochs':[20,30], 'lr_all':[0.005, 0.010], 'n_factors':[50,100] } #3-폴드 교차검증을 하고 두 개의 비용함수를 사용(RMSE, MAE) gs=GridSearchCV(SVD, param_grid, measures=['rmse','mae'],cv=3) gs.fit(data)#RMSE print("Best RMSE score attained : ", gs.best_score['rmse']) print("Best RMSE params : ", gs.best_params['rmse']) #Best RMSE score attained : 0.8990494796354239 #Best RMSE params : {'n_epochs': 20, 'lr_all': 0.005, 'n_factors': 50} #MAE print("Best RAE score attained : ", gs.best_score['mae']) print("Best RAE params : ", gs.best_params['mae']) #Best RAE score attained : 0.6927510126223377 #Best RAE params : {'n_epochs': 20, 'lr_all': 0.005, 'n_factors': 50} ''' RMSE와 MAE의 차이점? 제곱 1보다 작은 값을 제곱하면 더 작아지고 1보다 큰 값을 제곱하면 더 커짐 에러를 측정할 때 제곱이 들어가면 차이가 적을 땐 덜 신경쓰고 차이가 클 때는 증폭 '''3. 최고의 성능을 보인 파라미터로 모델 훈련하고 예측해보기
#비어있는 모델에 최적의 파라미터를 세팅 svd=gs.best_estimator['rmse'] trainset=data.build_full_trainset() #최적의 파라미터를 가지고 모델 build svd.fit(trainset)uid=str(196) iid=str(302) pred=svd.predict(uid, iid, verbose=True) #user: 196 item: 302 r_ui = None est = 3.81 {'was_impossible': False} #예측값(est)이 3.81로 나왔는데 실제값(r_ui)은 4임 굉장히 비슷한 값이 나온 것을 알 수 있음4. train/test split로 훈련하고 성능 평가하기
from surprise import accuracy from surprise.model_selection import train_test_split trainset, testset=train_test_split(data, test_size=.25) svd=SVD() #비어있는 SVD생성(하이퍼파라미터는 default값이 들어감) svd.fit(trainset) #trainset으로 모델 훈련 predictions=svd.test(testset) #testset으로 test해서 predition결과를 받음 accuracy.rmse(predictions) #성능을 평가하고 싶은 지표(RMSE)를 주고 성능 평가 #RMSE: 0.9034 #실제값과 예측값의 차이의 평균이 0.9034정도 위에서 하이퍼 파라미터 여러개 한 것보다 성능이 좀 더 나쁨 #0.9034454307670402testset[0:10]
pred=svd.predict('665','4052', verbose=True) #user: 665 item: 4052 r_ui = None est = 2.67 {'was_impossible': False}pred=svd.predict('95','2762',verbose=True) #user: 95 item: 2762 r_ui = None est = 4.63 {'was_impossible': False}3. 오토인코더 소개
대표적인 비지도 학습을 위한 딥러닝 모델
데이터의 숨겨진 구조를 발견하면서 노드의 수를 줄이는 것이 목표 ->즉, 차원축소
입력 데이터에서 불필요한 특징들을 제거한 압축된 특징을 학습하려는 것
오토인코더의 출력은 입력을 재구축 : 최대한 비슷하게 나오도록 학습, 입력 데이터=예상 출력 데이터
4. 오토인코더 실습
5. 오토인코더 기반 추천 엔진 실습
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
최종프로젝트 ~3주차 (0) 2021.09.07 최종 프로젝트 ~2주차 (0) 2021.09.07 [16주차 - Day3] Basic Recommendation System 구현 II (0) 2021.08.19 [16주차 - Day2] Basic Recommendation System 구현 I (0) 2021.08.18 [16주차 - Day1] Recommendation system이란 (0) 2021.08.18