-
최종 프로젝트 ~2주차교육/프로그래머스 인공지능 데브코스 2021. 9. 7. 22:28728x90
stargan이랑 stylegan2 ada pytorch랑 고민하다가 stylegan2 ada pytorch를 사용하기로 했음
기록 1. 코랩에서 돌리는데 evaluate metrics부분에서 에러가 떠서 tick이 자꾸 0에서 멈추고 더이상 훈련이 진행 안 되는 이슈 발생->밤새서 구글링한 결과 버전문제였음 쪼꼼 허무ㅎ,,,
에러1.
userwarning: this dataloader will create 3 worker processes in total→ /usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py 여기서 189번째 줄self.num_workers=num_workers-1 로 해결
참고 자료
userwarning: this dataloader will create 3 worker processes in total - Google 검색
Size([3, 32, 32]) 6 frog 32 tensor([[0.2314, 0.1686, 0.1961, ..., 0.8471, 0.5922, ... UserWarning: This DataLoader will create 4 worker processes in total.
www.google.com
https://github.com/pytorch/xla/issues/2749
https://discuss.pytorch.org/t/guidelines-for-assigning-num-workers-to-dataloader/813
Guidelines for assigning num_workers to DataLoader
I realize that to some extent this comes down to experimentation, but are there any general guidelines on how to choose the num_workers for a DataLoader object? Should num_workers be equal to the batch size? Or the number of CPU cores in my machine? Or to
discuss.pytorch.org
에러2. /usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py:1051: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.) return forward_call(*input, **kwargs)
→이건 에러떠도 넘어가서 안 고쳐도 될 듯
에러3.
/usr/lib/python3.7/multiprocessing/semaphore_tracker.py:143: UserWarning: semaphore_tracker: There appear to be 22 leaked semaphores to clean up at shutdown len(cache))단일 프로세싱으로 해야한다는데 이것저것 해봐도 뭔가 고쳐지지가 않음
->얘가 젤 문제였다 이것만 고치면 다 돌아갈텐데 하고 구글링만 3~4시간한듯
해본 방법들
- 1번의 코드에서 self.num_workers=1 로 설정→실패
- 아래 코드 추가→training_loop.py, semaphore_tracker.py에 추가하면 에러→실패
- main.py에서 추가→달라지는 게 없음
import multiprocessing as mp #mp.set_start_method('fork') torch.multiprocessing.set_start_method('spawn', force="True")참고 자료들
https://github.com/pytorch/examples/issues/538
https://github.com/pytorch/pytorch/issues/2517
https://docs.python.org/ko/3/library/multiprocessing.html
https://github.com/pytorch/pytorch/issues/13883
https://discuss.pytorch.org/t/issue-with-multiprocessing-semaphore-tracking/22943
https://github.com/NVlabs/stylegan2-ada-pytorch/issues/131
https://github.com/NVlabs/stylegan2-ada-pytorch/issues/39
https://github.com/NVlabs/stylegan2-ada-pytorch/issues/72
→이 방법써서 해결한 거 같다!결국 버전문제였다니^^...local에서는 ~/.cache/torch_extensions/ 삭제
!pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 !pip install click requests tqdm pyspng ninja imageio-ffmpeg==0.4.3기록2. 자료 찾다가 추가로 찾은 것들(프로젝트와 관련X그냥 저장해두는 것)
코랩에서 CUDA버전 확인하는 방법
!nvcc --version코랩에서 cuda 버전 바꾸는 방법
https://stackoverflow.com/questions/51888118/how-to-downgrade-tensorflow-version-in-colab
기록3. stylegan2 ada pytorch train.py실행하기 전 데이터셋zip파일 준비
1. dataset 준비&정제
2. dataset zip파일로 압축
!zip -r outputfilename inputdir3. dataset_tool.py를 활용해 .tfrecord 포맷으로 convert
python dataset_tool.py \ --source {dataset.zip파일 path} \ --dest {output이 저장될 파일 path}4. train.py로 훈련
!python train.py --outdir outputdirpath \ --data datadirpath(3에서 만든 zip파일) \ --기타 옵션들 추가기록4. 구글 이미지 검색에서 크롤링해오는 코드
from selenium import webdriver from urllib.request import urlopen from selenium.webdriver.common.keys import Keys import time import urllib.request ''' #한국민족문화대백과사전(http://encykorea.aks.ac.kr/Search/List) 여기서 초상화 이름 추출 driver = webdriver.Chrome('C:/Users/cat7892/Downloads/chromedriver_win32/chromedriver.exe') driver.get('http://encykorea.aks.ac.kr/') elem = driver.find_element_by_tag_name("input") # 검색창에 a를 입력 elem.send_keys('초상화') # a를 검색 elem.send_keys(Keys.RETURN) name=[] for i in range(2,16): namelist = driver.find_elements_by_tag_name('strong') isimage=driver.find_elements_by_class_name('bx_r') isnamelist=[] isimagelist=[] for j in namelist: if j.text=='': continue isnamelist.append(j.text) for j in isimage: isimagelist.append(j.text) count = 0 for n in isnamelist: if isimagelist[count]=='회화': name.append(n) count+=1 if i==11: driver.find_element_by_link_text('다음').click() continue driver.find_element_by_link_text(str(i)).click() ''' # selenium 저장부분 name = ['키워드'] #검색 키워드 b = 500 #크롤링할 이미지 갯수 #크롬드라이버 설치경로 driver = webdriver.Chrome("C:/chromedriver.exe") driver.get('http://www.google.co.kr/imghp?hl=ko') # 위에서 따온 이름으로 검색 for a in name: elem = driver.find_element_by_name("q") # 검색창에 a를 입력 elem.send_keys(a) # a를 검색 elem.send_keys(Keys.RETURN) #스크롤해서 가장 아래 부분까지 내려가는 코드 SCROLL_PAUSE_TIME = 1 # Get scroll height last_height = driver.execute_script("return document.body.scrollHeight") while True: # Scroll down to bottom driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Wait to load page time.sleep(SCROLL_PAUSE_TIME) # Calculate new scroll height and compare with last scroll height new_height = driver.execute_script("return document.body.scrollHeight") if new_height == last_height: try: driver.find_element_by_css_selector(".mye4qd").click() except: break last_height = new_height #이미지 크롤링시작 images = driver.find_elements_by_class_name("Q4LuWd") count = 0 for image in images: try: image.click() time.sleep(2) imgUrl = driver.find_element_by_class_name("n3VNCb").get_attribute("src") urllib.request.urlretrieve(imgUrl, "크롤링한 파일 저장할 경로" + a + str(count) + ".png") count += 1 if count >= b: driver.get('http://www.google.co.kr/imghp?hl=ko') break except: print('except') pass티스토리 개빡친다 새벽에 특강 다 정리하고 실수로 완료 안 누르고 브라우저 껐더니 다 날아감^^...자동저장 외 않되
GAN특강
1. 확률분포
확률 변수가 특정한 값을 가질 확률을 나타내는 함수
ex)주사위를 던졌을 때 나올 수 있는 수를 확률변수 X라고 가정하면 X는 1,2,3,4,5,6의 값을 가질 수 있음
P(X=1)=P(X=2)=P(X=3)=P(X=4)=P(X=5)=P(X=6)=1/6
- 이산확률분포 : 확률변수 X의 개수를 정확히 셀 수 있을 때 ex)주사위
- 연속확률분포 : 확률변수 X의 개수를 정확히 셀 수 없을 때(확률밀도함수를 이용해 분포를 표현) ex)키, 몸무게
ex)정규분포를 따를 때 μ+2σ는 상위 2%정도에 해당 f(μ+2σ)=0.02275
이미지 데이터에 대한 확률 분포
이미지 데이터는 다차원 특징 공간의 한 점으로 표현됨
사람의 얼굴에는 통계적인 평균치가 존재할 수 있고 모델은 이를 수치적으로 표현
이미지에서 다양한 특징들이 각각의 확률 변수가 되는 분포
생성 모델(Generative Models)
실존하지 않지만 있을 법한 이미지를 생성할 수 있는 모델
목표 : 시간이 지나면서 생성 모델 G가 원본 데이터의 분포를 학습하여 원본 데이터의 분포를 근사
모델 G의 학습이 잘 되었다면 원본 데이터의 분포를 근사할 수 있고 통계적으로 평균적인 특징을 가지는 데이터를 쉽게 생성가능
2. 오토 인코더(Auto Encoder)
차원의 저주(curse of dimensionality)
고차원의 희소한 데이터
차원 축소(Dimension Reduction)
유의미한 데이터들을 살펴보면 manifold(유의미한 정보를 가지고 있는 다면체)의 형태를 띄고 있으므로 차원을 축소하여 차원의 저주를 해결
Basic Auto-Encoder(AE)
입력과 출력을 같은 차원으로 두고 중간에 작은 차원을 가지도록 하는 것

Variational Auto-Encoder(VAE)
분포를 가우시안 분포를 갖게 만들어 controllable하게 만든 것
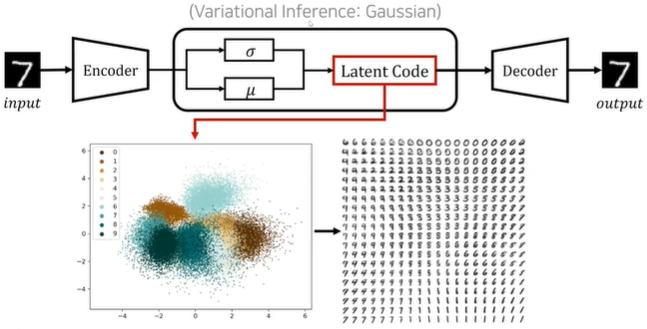
디코더 부분을 활용하면 이미지를 생성할 수 있게 됨
하지만 오토 인코더는 현재 잘 사용하지 않는데 이미지를 생성하게 되면 blurry한 이미지가 생성되는 문제가 있기 때문
->GAN의 등장
3. GAN(Generative Adversarial Networks)
생성자(generator)와 판별자(discriminator) 두 개의 네트워크를 활용한 생성 모델
목적 함수(objective function)를 통해 생성자는 이미지 분포를 학습할 수 있음
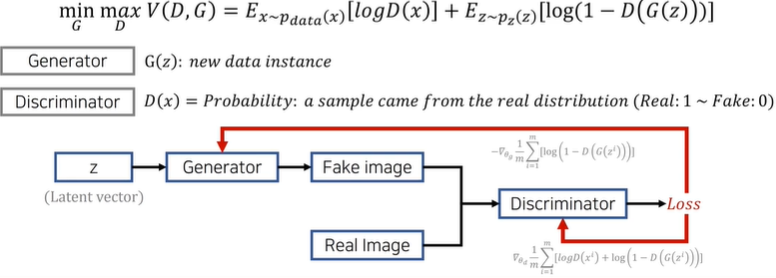
V:전체 목적함수,D는 최대화 G는 최소화하면서 경쟁/z:noise GAN에서 기댓값 계산 방법
모든 데이터를 하나씩 확인하여 식에 대입한 뒤에 평균을 계산
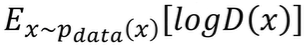
원본 데이터 분포에서의 샘플 x를 뽑아 logD(x)의 기댓값 계산
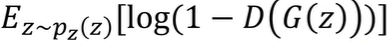
노이즈 분포에서의 샘플 z를 뽑아 log(1-D(G(z)))의 기댓값 계산
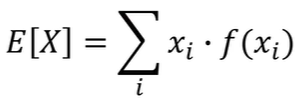
이산확률변수에 대한 기댓값 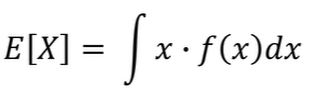
연속확률변수에 대한 기댓값 GAN의 수렴과정

GAN알고리즘
- 매번 학습을 시킬 때마다
- k번의 스텝만큼 반복(모든 데이터를 확인할 때까지)
- 샘플 미니배치(m개의 노이즈 샘플들)를 가져와서 그럴싸한 이미지(G(z))를 만들어냄
- 샘플 미니배치의 실제 데이터들을 추출해옴
- discriminator학습
- discriminator 학습이 끝난 후에
- discriminator를 속일 수 있도록 generator를 학습
- k번의 스텝만큼 반복(모든 데이터를 확인할 때까지)
Discriminator랑 Generator가 동시에 서서히 좋아질 수 있도록 해야함
한 쪽이 너무 강하게 학습되면 동작을 잘 못 함
GAN의 장점 : 원본 데이터를 잘 따라하면서 같지는 않게 잘 만듦, 샤프한 이미지 생성
DCGAN(ICLR 2016)
Deep Convolutional Layer를 이용하여 이미지 도메인에서 높은 성능
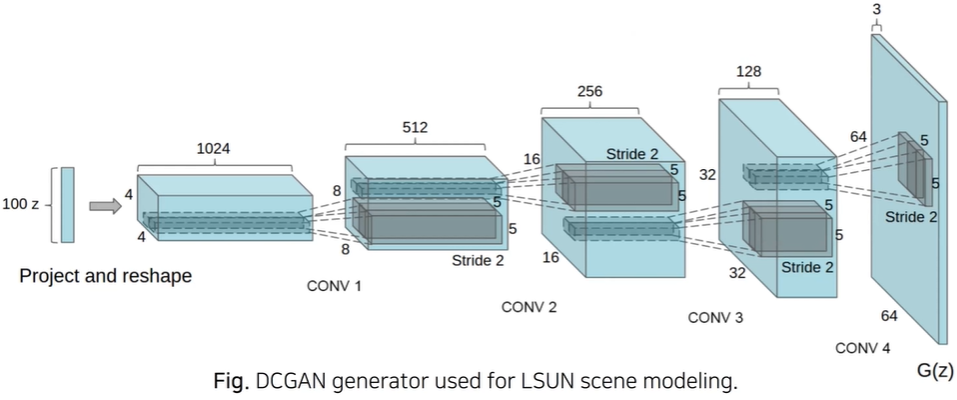
DCGAN에서의 Convoluion Filter
판별자(Discriminator): Strided Convolution을 사용해서 너비와 높이를 감소
생성자(Generator) : Transposed Convolution을 사용해서 너비와 높이를 증가
DCGAN의 Vector Arithmetic
ex)안경 쓴 남자-안경 안 쓴 남자+안경 안 쓴 여자=안경 쓴 여자
4. Conditional GAN(cGAN)
데이터의 모드(mode)를 제어할 수 있도록 조건(condition)정보를 함께 입력하는 모델
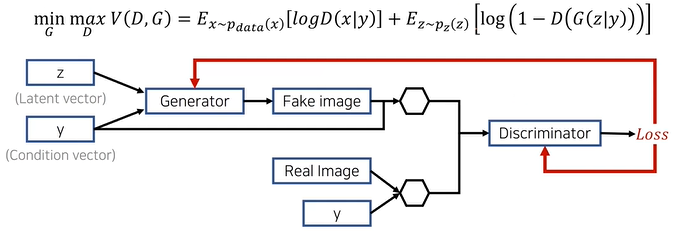
5. Image-to-Image Translation
1. Pix2Pix
Pix2Pix의 개요
학습과정에서 이미지 x 자체를 조건(condition)(클래스가 아닌 이미지로 입력!)으로 입력받는 cGAN의 한 유형
Pix2Pix는 픽셀들을 입력으로 받아 픽셀들을 예측한다는 의미
Pix2Pix의 아키텍처
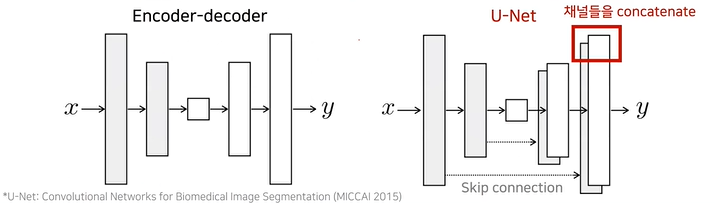
Pix2Pix는 이미지를 조건으로 입력받아 이미지를 출력으로 내보냄
이를 효과적으로 처리할 수 있는 U-Net기반 네트워크 아키텍처를 사용
U-Net은 입력과 출력이 같은 차원이고 초기의 피처값 자체를 나중에도(디코더부분) 그대로 활용할 수 있는 장점이 있음
Pix2Pix의 손실함수
유클리드 거리는 가능한 모든 출력을 평균화하는 L2손실함수는 blurry한 이미지를 생성함
성능을 향상시키기 위해 L1손실함수를 사용함
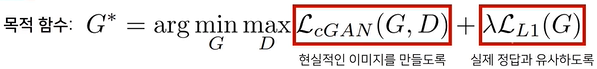
Pix2Pix의 Discriminator
convolutional PatchGAN분류 모델을 사용
이미지 내 패치 단위로 진짜/가짜 여부를 판별
장점 : 파라미터가 적음, 빠름, 이미지의 크기에 구애받지 않음
Pix2Pix의 한계점
서로 다른 두 도메인 X,Y의 데이터를 한쌍으로 묶어 학습을 진행해야하지만 그렇지 않은 경우도 존재
->Cycle GAN으로 해결!
2. CycleGAN
CycleGAN의 개요
G(x)가 다시 원본 이미지 x로 재구성될 수 있는 형태로 만들어지도록 함
원본 이미지의 contentㄴ는 보존하고 도메인과 관련한 특징을 바꿀 수 있음
이를 위해 2개의 변환기(translator)를 사용 : G(X->Y), F(Y->X)
Cycle-consistency loss를 사용
CycleGAN 손실함수
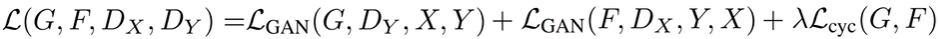
한 쌍으로 묶이지 않은 데이터셋을 사용하기 위하여 사이클(cycle)손실을 이용
3. WGAN-GP(NIPS 2017)
함수가 1-Lipshichtz 조건을 만족하도록 하여 안정적인 학습을 유도
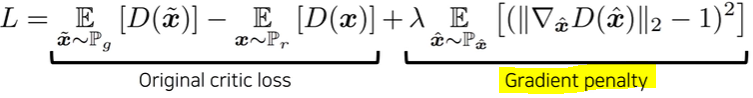 더보기
더보기1-Lipschichtz?
립시츠 연속 함수(Lipschitz-continuous function)는 두 점 사이의 거리를 일정 비 이상으로 증가시키지 않는 함수
k-Lipschichtz는 1차 도함수가 일부 상수 k에 의해 제한
k의 최소값을 함수의 Lipschitz상수라고함
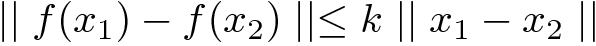
Lipschitz 함수의 속성 Lipschitz함수의 속성에 의해 x1과 x2가 서로 가깝다면 예측값인 f(x1)과 f(x2)도 가깝다는 것을 의미
적대적 공격(Adversarial Attacks)에 자주 사용됨 노이즈는 작게 사용하면서 예측을 틀리게 만들 수 있기 때문인 듯
참고 링크 : https://towardsdatascience.com/building-lipschitz-networks-with-deel-lip-68452d7bc2bc
4. StarGAN(CVPR 2018 Oral)
다중 도메인에서 효율적인 image to image translation 네트워크
하나의 뉴럴 네트워크를 이용해 다중 도메인(multi domain)사이에서의 이미지 변환이 가능
기존 image-to-image translation 아키텍처를 그대로 이용한다면 여러개의 네트워크가 필요
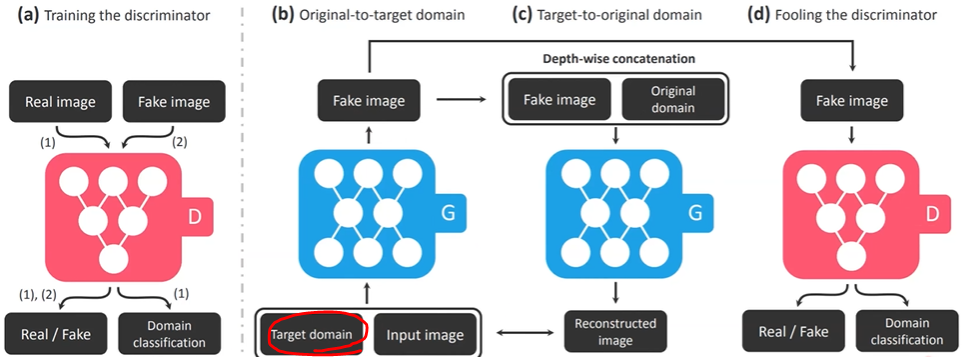
CycleGAN에 Target domain정보가 추가됐다고 생각하면 됨 StarGAN Loss function

Adversarial loss : 그럴싸한 이미지 생성
Domain classification loss : 해당 도메인(c)의 정보를 갖고 있는지 판단
Reconstruction loss : 원래 도메인(c')으로 되돌아오게 만드는 cycle loss(원래 콘텐츠는 유지하면서 원하는 특성만 바꾸도록 해줌) 사용
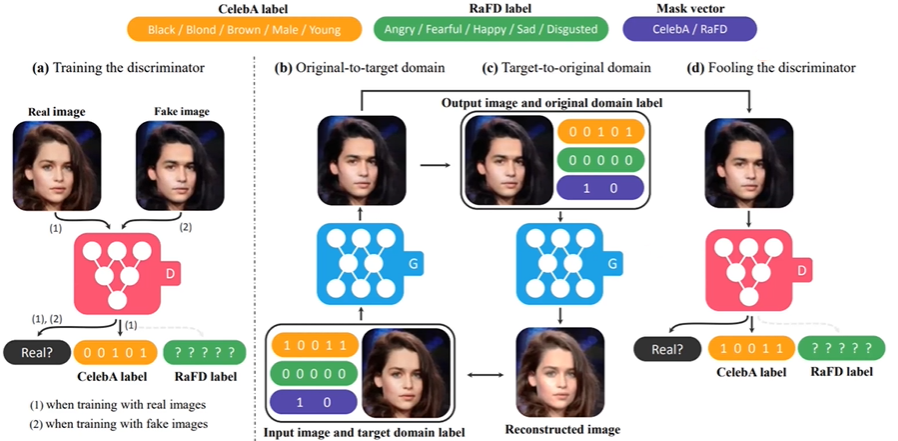
Mask Vector
Multiple dataset에서의 학습을 위해서 Mask vector m을 사용
요거 조금 더 찾아보기
적은 데이터를 최대한 활용하게 됨
6. SinGAN(ICCV 2019)
Learning a Generative Model from a Single Natural Image 즉, 한장의 이미지를 이용해 GAN네트워크 학습
다양한 애플리케이션에서 활용 가능 ex)이미지 수정, 애니메이션, 초해상도 등
전체 파이프라인 설명
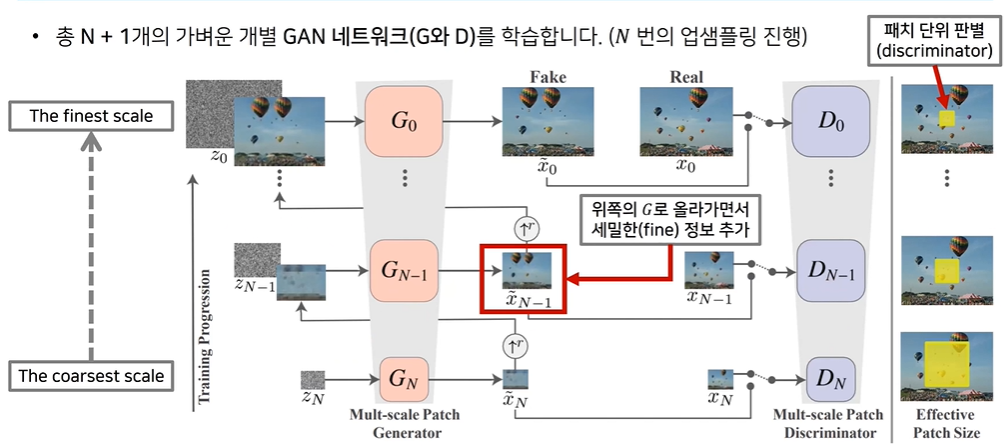
SinGAN아키텍처 : Single Scale Generation
하나의 스케일에서 사용되는 생성자는 잔여학습(resiual learning)을 이용하여 세밀한(fine) 정보를 추가하는 방식 사용
생성자는 5개의 블록으로 구성(각 블록은 conv(3*3)-BatchNorm-LeakyReLU형식)
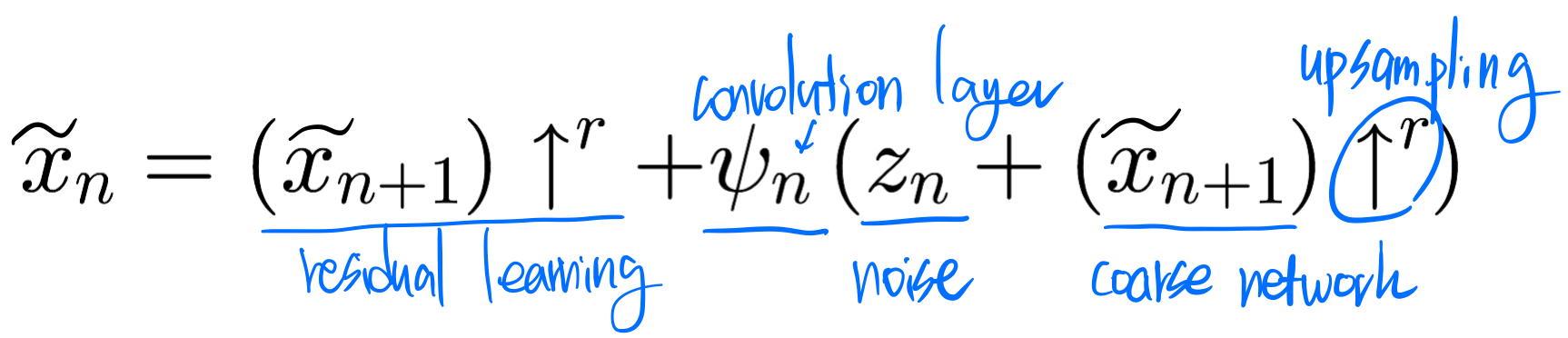
생성자가 수행하는 연산 SinGAN의 목적함수
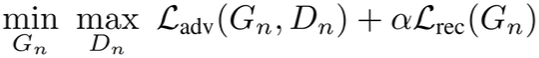
한번 학습이 완료되면 coarse scale의 생성자는 고정되어 업데이트되지 않음
- Adversarial loss(L_adv(G,D)) : 실제 이미지 x내의 패치와 가짜 이미지 x^~내 패치의 분포가 같도록 학습
- Markovian discriminator : 입력의 각 overlapping된 패치들에 대해서 진위 여부 판별
- WGAN-GP : GAN네트워크를 안정적으로 학습하도록 도와줌
- Reconstruction loss(L_rec(G)) : 실제 이미지x를 정확히 생성할 수 있도록 학습
- 노이즈의 값으로 0을 넣었을 때 실제 이미지와 동일한 이미지 생성
SinGAN의 기본적인 사용 방법
학습된 SinGAN의 생성자를 사용할 때는 원하는 스케일부터 시작하도록 설정할 수 있음
가짜이미지에 다운샘플링된 실제 이미지를 넣고 Gn-1부터 이용한다면 원본 이미지의 가장 coarse한 내용은 유지한 상태로 세밀한 정보를 다양하게 변경해볼 수 있음

n=N이면 다양성은 높지만 그럴싸하지 않음 7. StyleGAN(CVPR 2019)
고화질 이미지 생성에 적합한 아키텍처를 제안
연구배경 : Progressive Growing of GANs(PGGAN=ProGAN)
학습을 단계적으로 해상도를 높임(GAN이 처음부터 고해상도를 만들려고 하면 어려움)
학습과정에서 레이어를 점진적으로 추가함(즉, 모델 아키텍처가 학습하는 동안 계속 바뀜)으로써 고해상도 이미지 학습성공
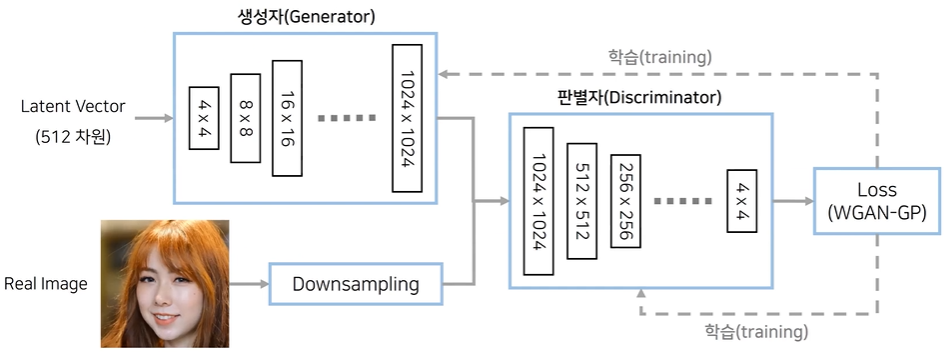
StyleGAN StyleGAN의 핵심 아이디어 : 매핑 네트워크(Mapping Network)
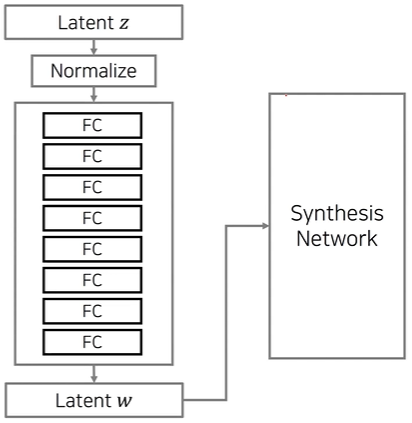
vector z를 바로 넣는 게 아니라 FC layer 여러개(매핑 네트워크)를 거쳐서
w를 생성하고 w에서부터 이미지를 생성할 수 있도록 함
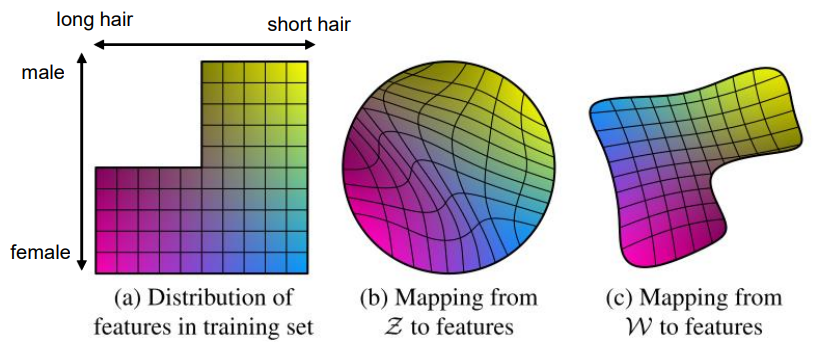
z(노이즈)를 추출할 때는 일반적으로 uniform이나 gaussian에서 샘플링을 많이 함
->샘플링 공간이 한정되어 있음, 이미 정의되어 있는 샘플링 공간을 사용하므로 데이터가 일그러질 수 있음
관련 연구 : Adaptive Instance Normalization(AdaIN)
AdaIN을 사용하면 다른 원하는 데이터로부터 스타일(style)정보를 가져와 적용할 수 있음
학습시킬 파라미터가 필요하지 않고 feed-forward방식의 style transfer 네트워크에서 사용되어 좋은 성능을 보임
Style Modules(AdaIN)
별도의 AdaIN레이어를 사용해서 스타일 정보를 넣어주는 방식으로 동작
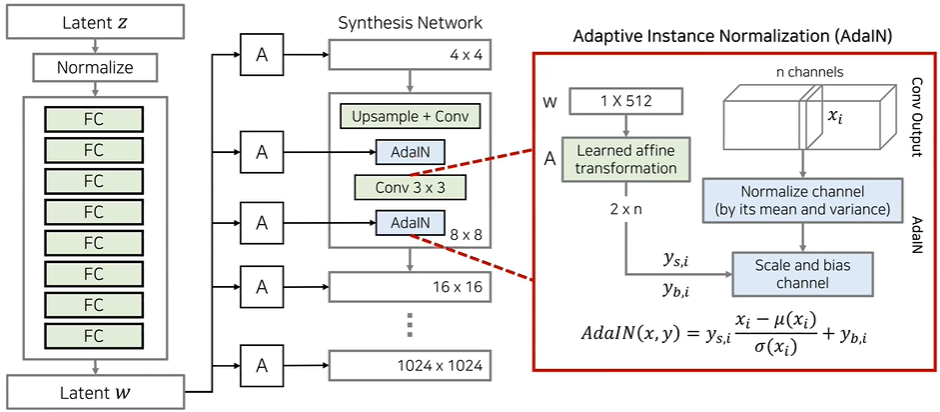
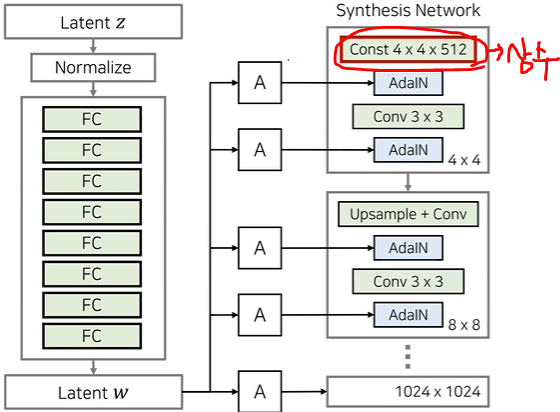
레이어마다 서로 다른 스타일들이 들어가도록 만들기 때문에 생성된 이미지가 여러 개의 스타일로 구성 Removing Traditional Input
Stochastic Variation
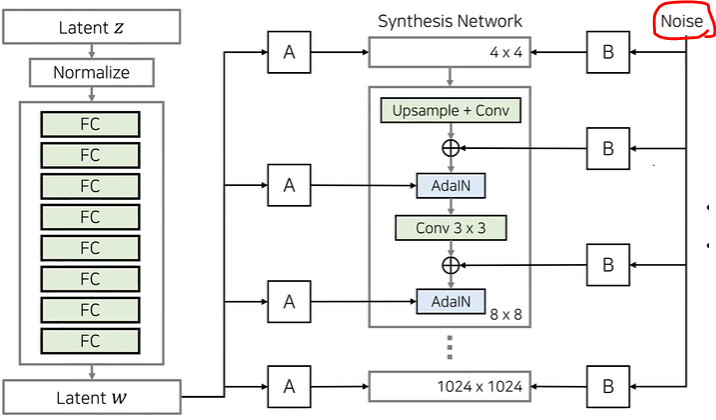
노이즈를 추가해주는데 이렇게 하면 다양한 확률적인 측면 컨트롤 가능
스타일은 high-level global attributes ex)얼굴형, 포즈, 안경의 유무 등
노이즈는 stochastic variation ex)주근깨, 피부 모공, 머리카락의 배치 등
Latent Vector Meanings of StyleGAN

8. StyleCLIP(2021)
학습이 잘 되어 있는 styleGAN을 활용해서 이미지를 텍스트로 컨트롤
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
최종프로젝트 ~4주차 (0) 2021.09.14 최종프로젝트 ~3주차 (0) 2021.09.07 [16주차 - Day4] Deep Learning 기반의 Recommendation System 구현 I (0) 2021.08.20 [16주차 - Day3] Basic Recommendation System 구현 II (0) 2021.08.19 [16주차 - Day2] Basic Recommendation System 구현 I (0) 2021.08.18