-
[13주차 - Day5] NLP: 단어 임베딩교육/프로그래머스 인공지능 데브코스 2021. 8. 10. 09:33728x90
단어 임베딩
단어의 의미를 어떻게 나타낼 것인지에 대한 고민
- 동의어(synonyms)라고 해서 항상 그 단어로 대체할 수 있는 것은 아님 ex)water=H2O, big=large
- 동의어는 아니지만 유사성(similarity)을 가진 단어들도 많음
- semantic field(특정한 주제, 영역을 공유하는 단어들)로 연관되어있을수도 있음 ex)restaurant-waiter, menu, plate, food등
- semantic frame(특정 행위에 참여하는 주체들의 역할에 관한 단어들)공유로 연관되어 있을수도 있음 ex)buy, sell, pay등
단어를 벡터로 의미 표현
단어들은 주변의 환경(주변의 단어들의 분포)에 의해 의미가 결정됨
만약 두 단어 A와 B가 거의 동일한 주변 단어들의 분포를 가지고 있다면 두 단어는 유사어
단어의 의미를 분포적 유사성(distributional similarity)를 사용해 벡터로 표현하고자 함
벡터공간 내에서 비슷한 단어들은 가까이에 있음
벡터로 표현된 단어 : 임베딩(embedding)
- 임베딩을 사용하지 않는 경우
- 각 속성은 한 단어의 존재 유무
- 학습 데이터와 테스트 데이터 사이 동일한 단어가 나타나지 않으면 예측 결과가 좋지 않을 것
- 임베딩을 사용하는 경우
- 각 속성은 단어 임베딩 벡터
- 테스트 데이터에 새로운 단어가 나타나도 학습 데이터에 존재하는 유사한 단어를 통해 학습한 내용이 유효하여 예측 결과가 괜찮을 것
임베딩의 종류
- 희소벡터(sparse vector)
- tf-idf
- Vector propagation
- 밀집벡터(dense vector)
- Word2vec
- Glove
각 문서는 단어들의 벡터로 표현됨, 문서벡터(Term-document행렬)

문서(작품)들에 나타난 단어들의 빈도수 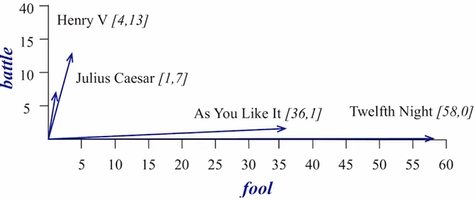
벡터를 시각화, 관련성이 있는 문서가 비슷한 방향으로 향하는 것을 볼 수 있음 단어 벡터

문서의 갯수가 제한되어있기 때문에 단어의 특성을 나타내기에 부족할 수 있음
word-word 행렬(term-context 행렬)
주변 단어들의 빈도를 벡터로 표현

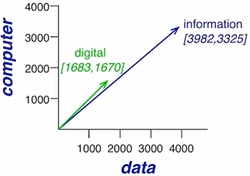
길이보다는 방향이 중요하다는 것을 알 수 있음
방향이 비슷하면 유사한 단어
벡터의 유사도 계산하기
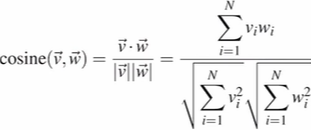
cosine을 사용해서 벡터의 유사도계산
값이 작으면 두 벡터 사이의 각도가 큼->유사 ↓
값이 크면 두 벡터 사이의 각도가 작음->유사 ↑
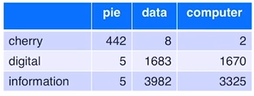
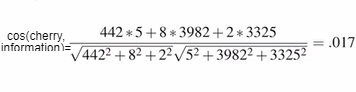
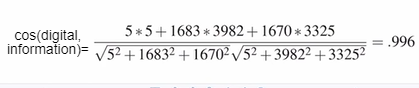
벡터 유사도 계산 예제 , 'digital'과 'information'의 값이 큼->두 단어의 유사도가 큰 것을 알 수 있음 1. TF-IDF
단어의 빈도수를 그대로 사용할 때의 문제점 : 자주 나타나는 단어들은 의미를 구별하는데 도움이 되지 않음
->문서 d내의 단어 t의 새로운 가중치 값을 계산
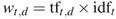
Term Frequency(tf)
document에 나타나는 단어의 빈도수
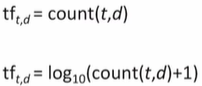
log를 씌워줘서 smoothing을 시켜서 값이 급격하게 올라가는 걸 방지하고 빈도수가 0인 경우 음의 무한대가 나올 수 있기 때문에 +1 시켜줌
Document Frequency(df)
단어 t를 포함하는 문서들의 개수
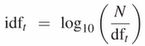
inverse df(idf) 최종적으로는 tf와 idf를 곱하게 됨
빈도수 기반과 tf-idf와 비교

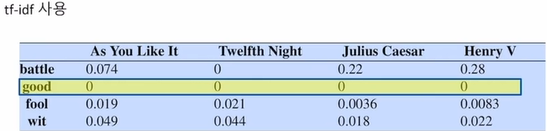
빈도수 기반에서 good이 큰 값을 가지는 것을 볼 수 있는데 good은 굉장히 많은 문서들에 등장해서 변별력없는 단어
->tf-idf에서는 0으로 나타남!
빈도수 기반에서 나오는 값을 tf-idf에서 보정해줌으로써 문서들간의 유사성 관계를 더 잘 표현
정보 검색에도 많이 쓰임 ex)사용자의 검색어가 들어왔는데 해당 문서에서 그 검색어가 변별력이 없지만 빈번하게 나타났다고 해서 상위에 노출시켜야 할까??->tf-idf를 이용해서 단어의 영향력을 보정시키는 방법 사용
지금까지 살펴본 건 희소벡터
tf-idf vector : vocabulary가 길어서 차원이 큼, 희소 벡터를 사용(대부분의 원소가 0)
word2vec, Glove : vocabulary가 짧고 밀집 벡터를 사용(대부분의 원소가 0이 아님)
밀집 벡터(Dense Vector)가 선호됨
- 더 적은 개수의 학습 파라미터를 수반
- 더 나은 일반화 능력
- 동의어, 유사어를 더 잘 표현
2. Word2vec
단어 w가 주어졌을 때 단어 c가 주변에 나타날 확률은?
예측 모델의 최종 예측값이 아니라 모델 내 단어 w의 가중치 벡터에 집중
self-supervision방식이므로 사람이 수동으로 레이블을 생성할 필요가 없음
Skip-Gram
한 단어가 주어졌을 때 주변 단어를 예측할 확률을 최대화하는 것이 목표
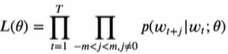
우도함수 파라미터 θ={W,C} W는 목표(또는 입력)임베딩 행렬, C는 상황(또는 출력)임베딩 행렬

w라는 단어가 주어졌을 때 c라는 단어의 확률
단어 사이의 유사성, 관계를 나타낼 수 있음

주어진 입력단어 w의 학습형태
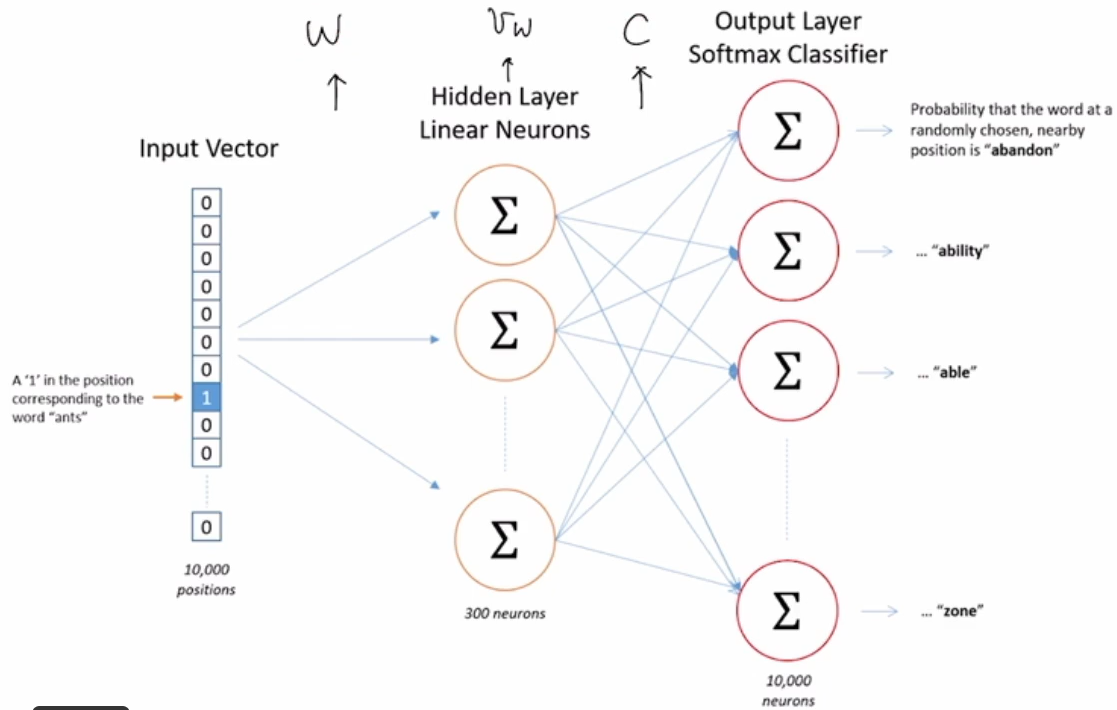
V의 크기가 클수록 계산량이 증가하는 문제
->Noise-Constrastive estimation(NCE)로 해결
Word2vec 학습과정 요약
- |V|개의 d차원 임베딩을 랜덤하게 초기화
- 주변 단어들의 쌍을 positive example로 생성
- 빈도수에 의해 추출된 단어들의 쌍을 negative example로 생성
- 위 데이터를 사용해 분류기 학습
- 학습된 임베딩 w가 최종 결과물
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[14주차 - Day3] Visual Recognition: 물체인식, 전이학습기반 커스텀 영상인식, 영상기반 이물질 검출 (0) 2021.08.10 [14주차 - Day2] NLP: Transformer와 BERT (0) 2021.08.10 [13주차 - Day4] NLP: 문서분류 (0) 2021.08.10 [13주차 - Day3] NLP: 언어모델 (0) 2021.08.10 [13주차 - Day2] NLP: 텍스트 전처리 (0) 2021.08.10