-
[13주차 - Day4] NLP: 문서분류교육/프로그래머스 인공지능 데브코스 2021. 8. 10. 09:33728x90
문서분류(Text Classification)
텍스트를 입력으로 받아 텍스트가 어떤 종류의 범주에 속하는지를 구분하는 작업
ex)문서의 범주,주제 분류/이메일 스팸 분류/감성 분류/언어 분류
문서분류의 정의
- input : d(document), C(fixed set of classes)={C1, C2, ..., Cj}
- output : predicted class(c∈C)
문서분류 방법들
1. 규칙 기반 모델
단어의 조합을 사용한 규칙들을 사용
ex)이메일 스팸분류 : 블랙리스트 이메일주소 or 이메일 내용의 단어(ex.dollars, you have been selected등)
사람이 규칙을 만들어서 precision은 높지만 예외가 많기 때문에 recall이 낮음
->머신러닝이 학습해서 규칙을 만들어내는 방법 사용 ex)Snorkel
더보기Snorkel
각각의 규칙을 labeling function으로 간주
graphical model의 일종인 factor graph를 사용해서 확률적 목표값을 생성하는 생성모델
프로젝트 초기 labeled data가 부족하거나 클래스 정의 자체가 애매한 경우(규칙을 생성하는 것은 쉽다고 가정)에 유용
확률적 목표값이 생성된 후엔 다양한 모델을 사용가능
2. 지도 학습
- input : d(document), C(fixed set of classes)={C1, C2, ..., Cj}, m(문서를 라벨링한 훈련세트)=(d1, C1), ..., (dm, Cm)
- output : d->c
다양한 모델 사용 가능
- Naive Bayes
- Logistic regression
- Neural networks
- k-Nearest Neighbors
- 기타 등등
1. Naive Bayes분류기
Naive Bayes가정과 Bag of words 표현에 기반한 간단한 모델
Bag of words? 순서를 고려하지 않는 단어들의 집합+각각의 단어들의 빈도 수
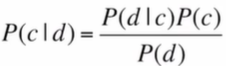
문서 d와 클래스 c 주어진 문서에 대해서 output으로 하나의 클래스를 출력해줘야함
그러려면 위의 조건부확률을 최대화시키는 클래스 C를 찾아서 출력

그래서 이것을 단순화시키는 과정이 필요한데 이를 위해 아래의 2가지 가정을 함
- Bag of words 가정 : 위치는 확률에 영향을 주지 않음
- 조건부독립 가정 : 클래스가 주어지면 속성들은 독립적
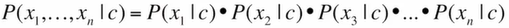
조건부독립과정 수식 ->클래스 c가 주어졌을 때 n개의 속성들이 주어질 확률은 분해가 된다

=Bayes Network : 확률변수들 사이의 독립적인 관계를 그래프표현
클래스가 주어져있을 때 각각의 x들은 독립적(conditional independence)
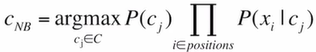
Naive Bayes를 문서분류에 적용하면 이와 같은 Naive Bayes를 문서분류에 적용하면 이와 같은 식이 나오게 됨
(xi는 각 포지션에 나타날 단어)
Naive Bayes분류기는 입력값에 관한 선형 모델
이걸 이해하려면 확률적 생성 모델에 대해 생각해봐야함

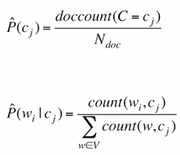
MLE training data가 충분하지 않으면 MLE가 0이 되는 문제가 발생할 수 있음
->모든 단어들의 최소빈도를 1로 설정하는 Laplace (add-1) smoothing으로 해결
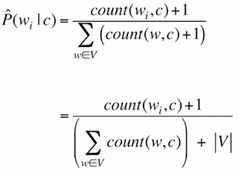
Laplace smoothing 
Naive Bayes분류기 - 학습 
Naive Byaes분류기 - 검증 
Naive Bayes 분류기 예제 Naive Bayes 분류기 요약
- 적은 학습데이터로도 좋은 성능
- 빠른 속도(training, inference)
- 조건부독립가정이 실제 데이터에서 성립할 때 최적의 모델
- 문서 분류를 위한 베이스라인(baseline) 모델로 적합
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[14주차 - Day2] NLP: Transformer와 BERT (0) 2021.08.10 [13주차 - Day5] NLP: 단어 임베딩 (0) 2021.08.10 [13주차 - Day3] NLP: 언어모델 (0) 2021.08.10 [13주차 - Day2] NLP: 텍스트 전처리 (0) 2021.08.10 [13주차 - Day1] Spark IV (0) 2021.08.10