-
[13주차 - Day2] NLP: 텍스트 전처리교육/프로그래머스 인공지능 데브코스 2021. 8. 10. 09:33728x90
자연어 처리
자연어의 의미를 컴퓨터로 분석해서 특정 작업을 위해 사용할 수 있도록 하는 것
참고자료
https://web.stanford.edu/~jurafsky/slp3/
Speech and Language Processing
Speech and Language Processing (3rd ed. draft) Dan Jurafsky and James H. Martin Here's our December 30, 2020 draft! Includes: new version of Chapter 8 (bringing together POS and NER in one chapter), new version of Chapter 9 (with Transformers) Chapter 11 (
web.stanford.edu
텍스트 전처리
단어(Word)
- Vocabulary : 단어의 집합
- Type : Vocabulary의 한 원소, 문장 내의 유니크한 Token
- Token : 문장 내에 나타나는 한 단어
ex)They picnicked by the pool, then lay back on the grass and looked at the stars.
token : 16개 type : 14개(the가 반복)
말뭉치(Corpus)
하나의 말뭉치는 대용량 문서들의 집합
말뭉치의 특성은 언어, 방언, 장르(뉴스, 소설 등), 글쓴이의 인구통계적 속성(나이, 성별, 인종 등)에 따라 달라지게 됨
텍스트 정규화
- 토큰화(tokenizing words)
- 단어정규화(normalizing word formats)
- 문장분절화(segmenting sentences)
Unix 명령으로 간단하게 토큰화하기
#1. 텍스트 파일 안에 있는 단어들 토큰화해서 한줄씩 띄워서 출력 tr -sc 'A-Za-z' '\n' < hamlet.txt #2. 빈도수로 정렬 '빈도수 단어'로 출력 tr -sc 'A-Za-z' '\n' < hamlet.txt | sort | uniq -c | sort -n -r #3. 소문자로 변환해서 정렬 tr 'A-Z''a-z' < hamlet.txt | tr -sc 'a-z' '\n' | sort | uniq -c | sort -n -r위의 방식처럼 단순하게 토큰화하면 생기는 문제점
- 문장부호들은 항상 무시할 수는 없다 ex)AT&T, ph.D., $12.50, 01/02/2021, http://www.yahoo.com, #ml, helloworld@email.com
- 접어(clitics) 다른 단어에 붙어서 존재하는 형태 ex)we're->we are
- 여러 개의 단어가 붙어야 의미있는 경우 ex)New York, rock'n'roll
한국어의 경우
토큰화가 복잡함->띄어쓰기 문제, 형태소(morpheme)의 문제
ex)열심히 코딩한 당신, 연휴에는 여행을 가봐요->열심히/코딩/한/당신/,/연휴/에는/여행/을/가봐요
->단어보다 작은 단위(subword)로 토큰화가 필요함을 알 수 있음
1. 텍스트 정규화 - Subword Tokenization
ex)만약 학습데이터에서 보지 못했던 새로운 단어가 나타난다면?
학습데이터 : low, new, newer
테스트데이터 : lower
->-er, -est 등과 같은 형태소를 분리할 수 있으면 좋을 것
Subword Tokenization Algorithms의 종류
- Bytes-Pair Encoding(BPE)
- WordPiece
- Unigram language modeling
Subword Tokenization Algorithms의 두가지 구성요소
- Token learner : 말뭉치에서 Vocabulary(token들의 집합)을 만들어냄
- Token Segmenter : 새로운 문장을 토큰화
1. Byte Pair Encoding(BPE)
- Vocabulary를 단일 문자들의 집합으로 초기화함
- 말뭉치에서 연속적으로 가장 많이 발생하는 두 개의 기호들(vocabulary내의 원소들)을 찾음
- 두 기호들을 병합하고 새로운 기호로 vocabulary에 추가
- 말뭉치에서 두 기호들을 병합된 기호로 모두 교체
- 2-4번을 k번의 병합이 일어날 때까지 반복

기호병합은 단어 안에서만 이루어짐
단어 끝을 나타내는 특수기호 '_'를 단어 뒤에 추가하고 각 단어를 문자단위로 쪼갬


1. e r을 er로 병합 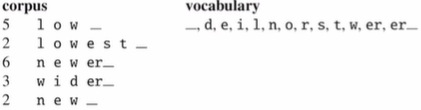
2. er _ 을 er_로 병합 
3. n e 을 ne로 병합 
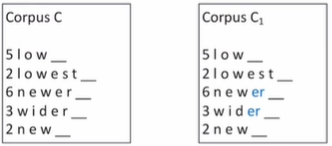
위의 방식을 계속해서 병합하면 이처럼 병합이 됨 2. Wordpiece
BPE는 빈도수를 이용하는 반면 Wordpiece는 likelihood를 최대화시키는 쌍을 찾음

3. Unigram
병합을 순차적으로 고려하지 않고 여러 개의 병합이 동시에 일어날 수 있게 likelihood계산
확률모델(언어모델)을 사용
- 학습데이터 내의 문장 : 관측(observed)확률변수로 정의
- 모든 가능한 tokenization : 잠재(latent) 확률변수로 정의
데이터의 주변 우도(marginal likelihood)를 최대화시키는 tokenization을 구함
더보기주변 우도(marginal likelihood)?
P(X, Z)를 Z에 대해 ∑한 것 = P(X) = 주변 우도 (X : 관측된 변수, Z : 잠재 변수)
->EM(Expectation maximization)을 사용하는데 E step과 M step중 M step의 Viterbi알고리즘 사용
2. 텍스트 정규화 - 단어정규화
단어들을 정규화된 형식으로 표현
why?같은 의미를 가진 단어인데 여러 형태인 경우 문제가 발생할 수 있으므로 해결해야함
ex)U.S.A=USA=US / uhhuh=uh-huh / Fed=fed / am=is=be=are 등
- Case folding : 모든 문자들을 소문자화함, 일반화(generalization)에 유용
- Lemmatization : 어근을 사용해서 표현 ex)am,are,is=be / car,cars,car's,cars'=car 등
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[13주차 - Day4] NLP: 문서분류 (0) 2021.08.10 [13주차 - Day3] NLP: 언어모델 (0) 2021.08.10 [13주차 - Day1] Spark IV (0) 2021.08.10 [12주차 - Day5] Spark 실습 (0) 2021.08.10 [12주차 - Day4] Spark III (0) 2021.08.10