-
Day15교육/서울 ICT 이노베이션 고오급 시각과정 2022. 9. 4. 13:15728x90
머신러닝의 주요작업은 학습 알고리즘을 선택해서 어떤 데이터에 훈련시키는 것
- 배치 학습에서의 머신러닝
- 입력 x에 대해 y를 출력하는 시스템 f(x)=y를 가정
- f는 실체를 알 수 없으므로 θ에 의해 정의되는 모델로 간주
- f는 알 수 없지만 수 많은 사례(x,y)를 통해 θ를 추정
- 만약 실제 시스템을 완벽히 복원했다면 f(x)-y=0
- 즉, 모델링된 시스템의 출력값 f(x)=ŷ가 실제 y에 가장 가까워지도록 하는 θ를 찾음
- 여기서 x,y는 상수(주어진 샘플)이고 θ는 우리가 찾고자 하는 값(모델에 대한 파라미터)
- 주어진 y에 f(x)가 최대한 가까워지는 과정이 훈련, 학습, 피팅
- 피팅이 잘 이루어진 정도를 에러를 통해 추정
- MSE(θ)=∑(f(x)-y)^2/N (에러 계산 방법은 다양함 ex)cross entropy, MAE...)
- 머신러닝이란 다음 최적화 문제를 푸는 것 :
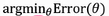
더보기f(x)=ax+b
=θ·x
=θ0x0(x0=1)+θ1x
에러(머신러닝)=로스(신경망)=cost(경사하강법) *() : 주로 쓰이는 곳
머신러닝 시스템의 종류
- 넓은 범주의 분류
- 사람의 감독하에 훈련하는 것인지 그렇지 않은 것인지 : 비도, 비지도, 준지도, 강화 학습
- 실시간으로 점진적인 학습을 하는지 아닌지 : 온라인 학습과 배치 학습
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자처럼 훈련 데이터셋에서 패턴을 발견하여 예측 모델을 만드는 지 : 사례 기반 학습과 모델 기반 학습
심층 신경망을 훈련할 때 마주할 수 있는 문제
까다로운 그레디언트 소실 또는 그레디어트 폭주 문제
심층 신경망의 아래쪽으로 갈수록 그레디언트가 점점 더 작아지거나 커지는 두 현상 모두 하위 층을 훈련하기 매우 어려움
비용문제
대규모 신경망을 위한 훈련 데이터가 충분하지 않거나 레이블을 만드는 작업에 비용이 너무 많이 들 수 있음
훈련이 극단적으로 느려지리 수 있음
과대적합
수백만 개의 파라미터를 가진 모델은 훈련 세트에 과대적합될 위험이 매우 큼, 특히 훈련 샘플이 충분하지 않거나 잡음이 많을 때 그럼
활성화 함수


초기화 전략
초기화 전략 활성화 함수 글로럿 활성화 함수 없음, tanh, logistic, softmax He ReLU함수와 그 변종들 르쿤 SELU 초기화 전략과 활성화 함수가 일치하면 입력이 표준분포의 경향이라면 과정도 표준분포를 따라 학습
그래디언트 소실과 폭주 문제를 확실하게 해결해주는 방법 : 배치 정규화
foward, backpropagation 둘 다 학습을 잘 해줌
- 배치 학습에서의 머신러닝