-
[15주차 - Day2] GAN, Style Transfer교육/프로그래머스 인공지능 데브코스 2021. 8. 11. 10:09728x90
1. GAN의 개요
Probability Density Function
PDF(=Probability Density Function) : 사건이 발생할 확률
Sample drawn from the PDF : PDF를 가진 사건에서 샘플을 뽑았을 때 나올 확률
영상을 만들어내는 PDF를 알고 있으면 영상을 생성할 수 있음!
PDF의 값이 큰 sample을 생성하면 됨
하지만 이 PDF를 구하는 것이 불가능
GAN(Generative Adversarial Network)
초기의 GAN
- Generator : George, 위조범으로 비유
- Disciminator : Danielle, 가짜돈과 진짜돈을 구별하는 사람으로 비유
서로 피드백을 주고받으면서 발전하다가 일정 능력치에 도달하면 George가 만든 돈이 Danielle이 구별 못하게 됨
이 때부턴 Danielle이 필요없어지고 George에게만 관심, 학습이 완료된 상태에 도달한 것
노이즈->generator->가짜->Discriminator(진짜와 비교)->가짜/진짜 피드백
GAN 최적화
분포 매핑함수로서의 GAN
가우시안 분포로부터 노이즈를 생성하고 이걸 입력으로 받아서 이미지를 생성하게끔함
Discriminator의 역할
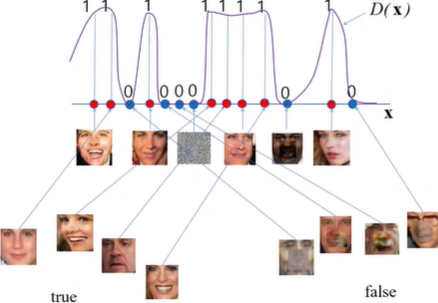
진짜 얼굴이 들어오면 높은 확률(1)을,가짜 얼굴이 들어오면 낮은 확률(0)을 출력해주는 역할
즉 Generator가 만든 얼굴은 가짜로 인식하게끔 하는 네트워크
->Generator는 Discriminator로부터 높은 확률을 가진 가짜 얼굴은 생성하고 낮은 확률을 가진 가짜 얼굴은 생성하지 않게 업데이트
Discriminator Network
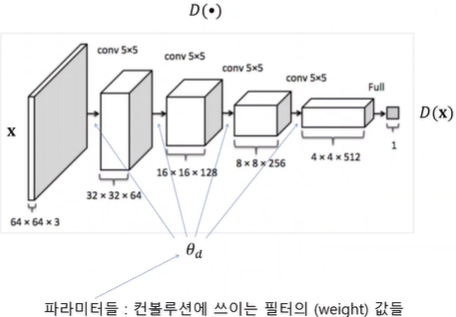
x(input, 입력영상 64*64*3)를 입력으로 받는 convolution network와 같았음
1짜리 output이 나오게 되는데 1이면 진짜 영상, 0이 나오면 가짜 영상이라고 판별
옵티마이저의 목표는 θd를 구하는 것
Generator Network
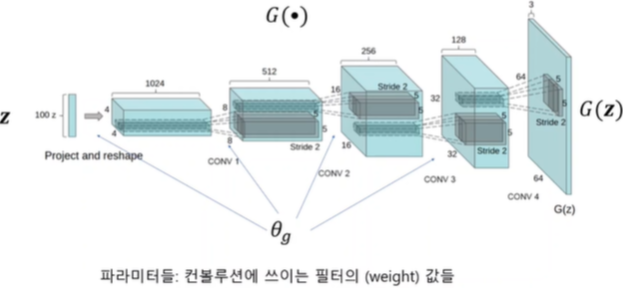
z(input, 100 noise)를 입력으로 받는 convolution network
output이 영상으로 나오게 됨
θg를 구하는 것이 목표
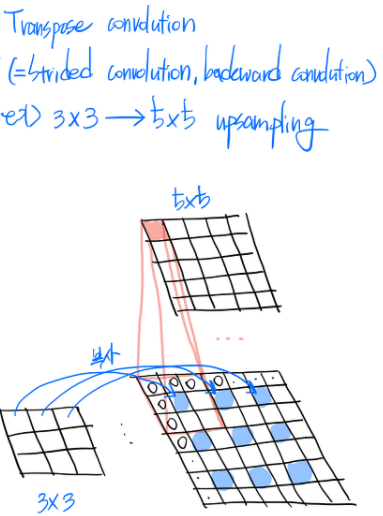
Strided Concolution
Cost Function
필터의 파라미터를 찾으려면 cost function을 최소화시켜야함

최적화방법



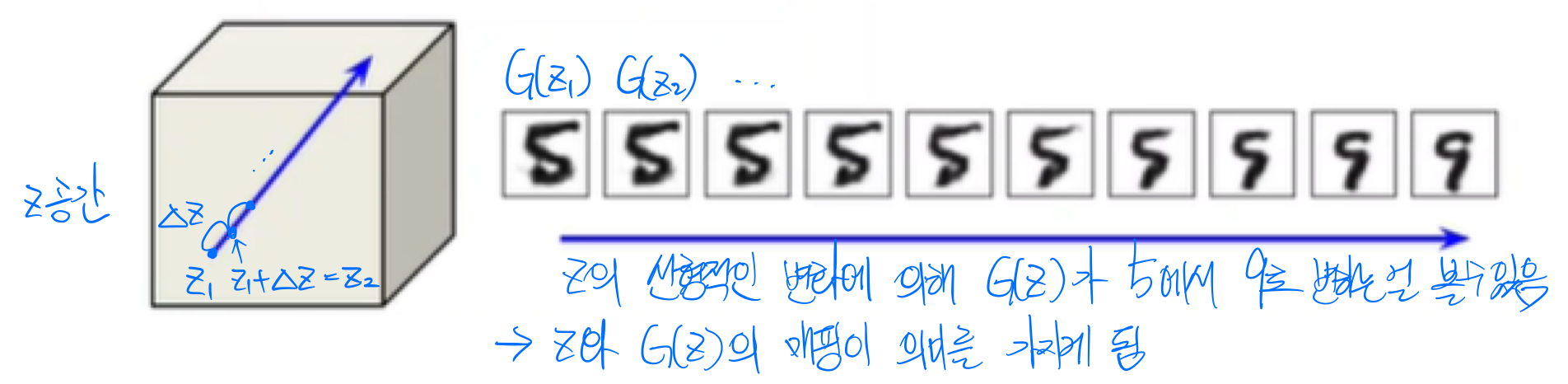
Walking in the latent Space
latent는 z를 말함
2. Universal Loss로서의 GAN
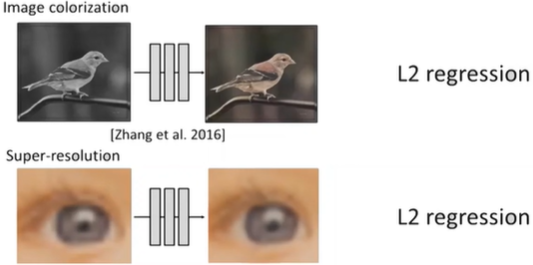
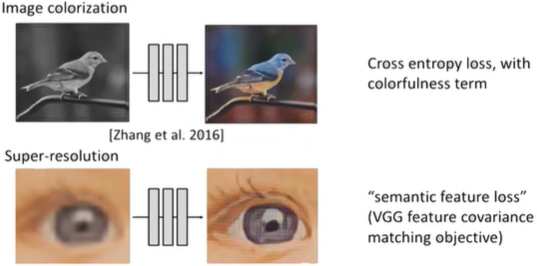
왼 : Fixed Loss/오 : Universal Loss 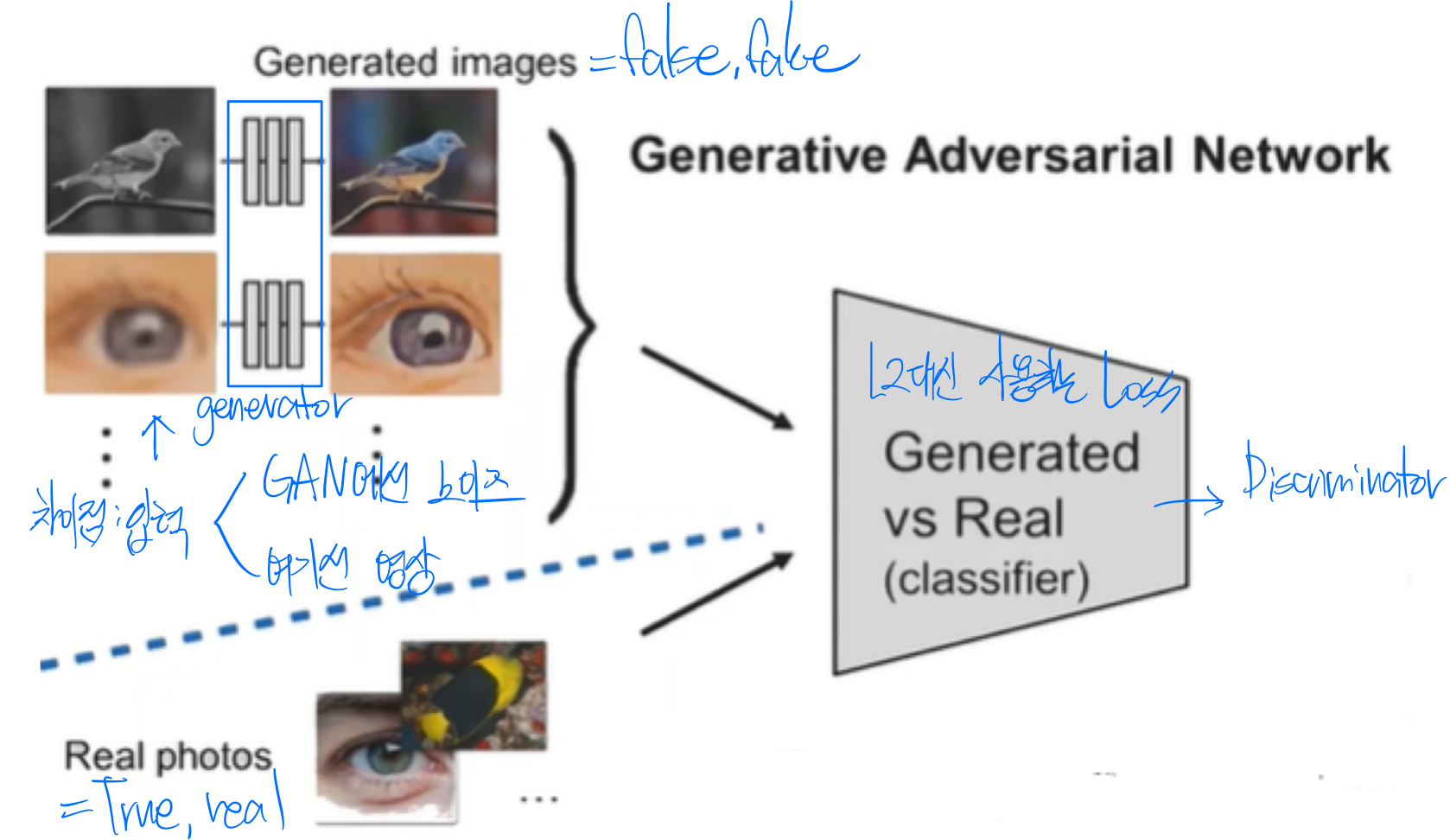
PatchGAN
1*1로 이미지를 보게 되면 대충 만들어도 discriminator를 속일 수 있기 때문에 generator가 제대로 생성 못 함
patch단위(receptive field)로 이미지를 나누고 discriminate
patch단위가 또 너무 커지면 너무 디테일만 봐서 전체적으로는 진짜같지 않은 이미지를 생성할수도 있음
Pix2Pix Loss함수
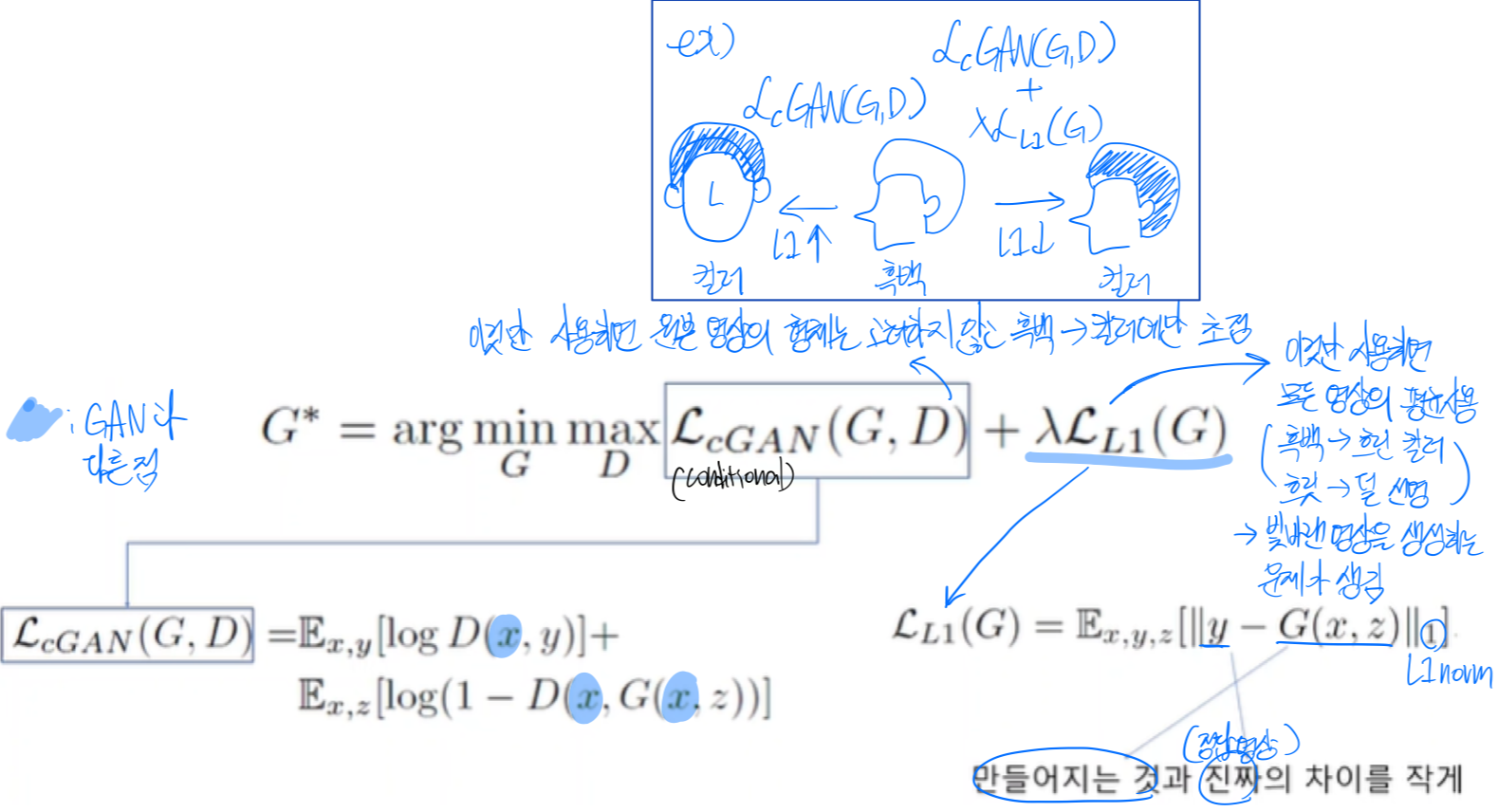
Conditional GAN

Stack GAN
text-to-image : https://arxiv.org/pdf/1612.03242.pdf
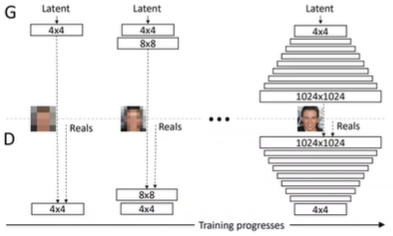
progressive GAN
처음부터 GAN이 high resolution을 만들기 힘드니까 점진적으로 발전할 수 있도록 downsampling된 영상을 보여주면서 점점 높은 픽셀로
Cycle GAN
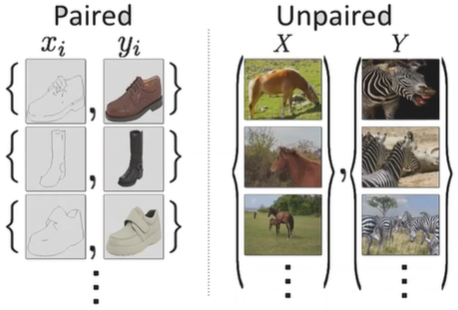
이전까지는 학습데이터가 쌍으로 들어갔음
하지만 현실에는 쌍으로 된 데이터가 많이 없음
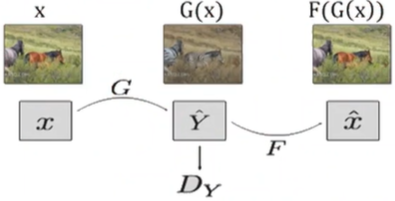
∥F(G(x))-x∥1이라는 제약 조건을 둠
->x(원본영상)와 F(G(X))(G를 통해 복원한 영상)의 차이가 적게 될 수 있게 학습
why?
G가 제대로 학습 못 했으면 복원도 힘들 것이기 때문에
CyCADA
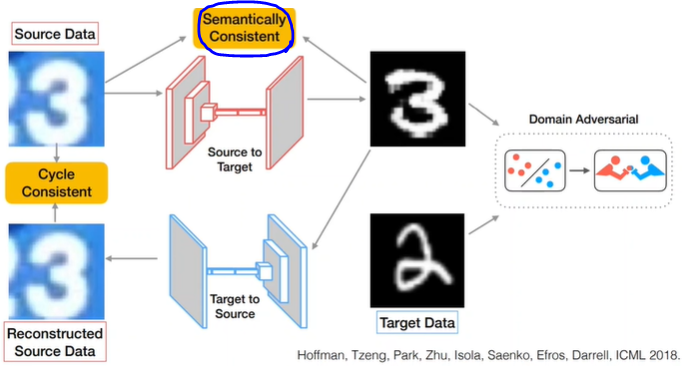
추가된 부분 Semantically Consistent
source data와 source to target을 거쳐나온 data의 label을 비교하는 과정 추가
3. Domain Adaptation
Domain Adaptation의 필요성
Dataset에는 bias가 있음 ex)자세가 다르다거나 밝기가 다르다거나 등
현실세계의 dataset에는 x는 있지만 y는 없거나 제한되어 있을수도 있음
Deep Domain Adaptation
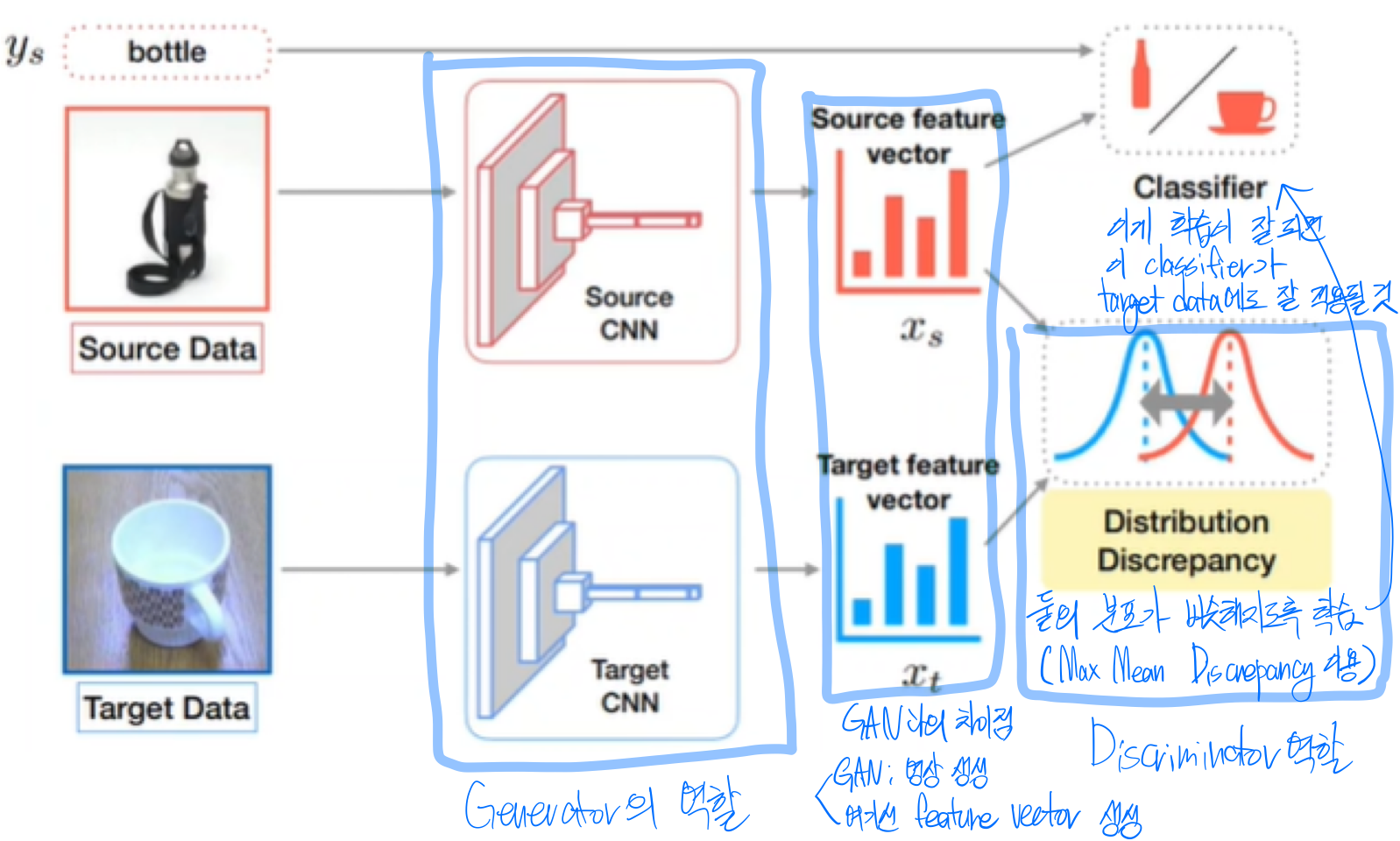
Domain Adversarial Adaptation
domain classifier도 학습시켜서 input이랑 target을 섞어서 경계를 새로 만들고 나서 classifier를 수행하면 수행이 잘 됨
4. Style Transfer

content영상에 style영상의 style을 전이하는 것이 목표
Style의 정의
특정 노드를 가장 크게 activate시키는 패치 영상을 layer로 차곡차곡 쌓음
Demystifying Neural Style Transfer
style loss에 대한 논문
maximum mean dependency를 먼저 이해해야함
'교육 > 프로그래머스 인공지능 데브코스' 카테고리의 다른 글
[16주차 - Day2] Basic Recommendation System 구현 I (0) 2021.08.18 [16주차 - Day1] Recommendation system이란 (0) 2021.08.18 [15주차 - Day1] MaskRCNN, GAN(Generative Adversarial Networks) (0) 2021.08.10 [14주차 - Day5] Visual Recognition: Object Segmentation, YOLO, SSD 기반의 Object Detection (0) 2021.08.10 [14주차 - Day4] Visual Recognition: Object Detection, Faster RCNN (0) 2021.08.10