-
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models(Nightshade)공부/논문 2024. 2. 22. 19:07728x90
https://arxiv.org/abs/2310.13828
Prompt-Specific Poisoning Attacks on Text-to-Image Generative Models
Data poisoning attacks manipulate training data to introduce unexpected behaviors into machine learning models at training time. For text-to-image generative models with massive training datasets, current understanding of poisoning attacks suggests that a
arxiv.org
Abstract
text-to-image모델은 데이터 오염 공격에 영향을 받지 않는 것 처럼 보임
해당 논문은 사실 이 모델이 이러한 공격에 매우 취약하다는 점을 보여줌
배경
1. 수백만, 수십억 개의 샘플로 훈련되지만 특정 개념이나 프롬프트와 관련된 훈련 샘플의 수는 일반적으로 수천 개에 이름
=>특정 프롬프트에 응답하는 모델이므로, 프롬프트 별 공격에 취약할 것
2. poison 샘플은 매우 적은 수의 샘플로도 성공할 수 있도록 효과를 극대화하도록 신중하게 제작될 수 있음
=>100개 미만의 poison train data sample을 사용하여 SD에서 출력을 제어할 수 있는 프롬프트 별 poison공격인 Nightshade개발
Nightshade는 시각적으로 양성 이미지와 동일하게 보이는 은밀한 poison 이미지를 생성하고 관련 개념에 poison 효과를 생성
독립적인 프롬프트에 대한 적당한 수의 공격으로 인해 모델이 불안정해지고 모든 프롬프트에 대한 이미지 생성 기능이 제어될 수 있음
목적 : 콘텐츠 소유자의 방어 수단으로 Nightshade 제안
1. Introduction
text-to-image 모델은 어마어마한 파급력을 가지고 창조 산업에 파괴적인 영향을 끼침
하지만 data poisoning attack에 대한 취약성을 고려한 사람은 거의 없었음
poisoning attack이란 훈련 데이터를 조작하여 훈련 시 모델에 예상치 못한 동작을 주입하는 것
poisoning attack은 잘못된 분류를 유발하지만 성공적으로 작동하려면 상당한 양의 poison 데이터 필요(약 20% 이상)
diffusion 모델은 수억, 수십억 개의 이미지로 학습되기 때문에 이러한 공격은 불가능하다고 가정하는 것이 일반적
하지만 시카고대학은 해냄!1. diffusion모델은 수백만 개의 이미지로 훈련되지만 특정 개념이나 프롬프트와 관련된 train data는 수천 개 정도로 매우 적음
=>"개념 희소성(concept sparsity)"라고 부르고, 이는 특정 대상 프롬프트에 응답하는 모델의 능력을 손상시키는 프롬프트 별 공격의 실행 가능성을 나타냄
2. 자연스러운 양성 이미지는 label, 이미지 구성, 이미지 특징에서 큰 변화를 만듦, 이를 통해 학습 영향을 최소화하기 위한 파괴적인 간섭을 생성
프롬프트별 poisoning attack에는 모델 내부 파이프라인에 접근하지 않아도 되고, 특정 대상 프롬프트를 재정의하기 위해 매우 적은 수의 poison 샘플만 필요(실제로 car=>cow로 프롬프트를 변경한 Nightshade 공격에 50개의 샘플만 사용해도 성공했다고 함, 그래서 모델은 자동차가 언급될 때마다 소의 이미지를 출력했다고 함 호달달)
Nightshade의 장점
1. poison sample이 인간의 눈에는 여전히 양성 이미지처럼 보이게 함
2. 매우 적은 수의 샘플로도 매우 성공적인 poison attack이 가능
3. concept에 "bleed through(스며드는)"하므로 프롬프트 교체를 한다고 피할 수 있는 것이 아님
ex)"fantasy art"에 대한 poisoning은 "dragon", "Michael Whelan(유명 판타지, SF 아티스트)"에도 영향
=>단일 프롬프트가 여러 개의 프롬프트에게 영향
4. Nightshade가 다양한 프롬프트에 영향을 미치는 경우, 기본 특징에 대한 모델의 이해를 손상시킴=>더 이상 의미있는 이미지 생성 불가
더보기기존의 이미지 스타일 모방 공격을 방해하는 모델들(Glaze, Mist)과 다른 점
기존도구들은 local fine-tuning(ex. 집에서 쬐끔씩 파인튜닝하려는 사용자들)을 방해하지만,
Nightshade는 모든 사용자들에 대해 기본 모델을 손상시키려 함
2. Background and Related Work
2.1. Text-to-Image Generation
Model Architecture
Text-to-Image모델은 GAN과 VAE로부터 diffusion모델로 발전
VAE를 이용하여 픽셀 공간으로부터 latent feature space로 이미지 변경하는 latent diffusion을 활용하여 품질, 비용 개선
모델은 낮은 차원의 이미지 특징 공간에서 diffusion 프로세스를 수행하여 비용을 대폭 줄이고, 훨씬 큰 데이터 셋에서 학습 가능
Training Data Sources
images/ALTtext pair의 다양하고 큰 데이터 셋을 학습함
SD나 DALLE-2와 같은 모델은 웹에서 스크랩한 5억~50억 개의 이미지 데이터셋을 학습
여기 쓰이는 데이터셋들은 수정이 되는데(전처리) 이로 인해 데이터 오염 공격이 발생할 가능성이 있음
Continuous Model Training
이전 버전에서 지속적으로 학습되거나, 특정 사용 사례에 맞는 새로운 데이터셋으로 학습
2.2. Data Poisoning Attacks
Data poisongin attack은 poison data를 학습 파이프라인에 주입하여 모델 성능을 저하를 일으킴
Poisoning Attaacks against Classifiers
분류기에 대한 공격은 잘 연구되어있음 ex)misclassifiacation attacks, backdoor attacks, clean-label backdoor attacks
이에 대응하는 방어도 잘 연구되어있음 ex)poison data를 탐지하는 데 집중하거나 학습시간동안 poison data의 영향을 완화하기 위한 훈련하거나 하는 방법들
하지만 뭐든 계속 진화하는 법 아니겠음?창과 방패의 싸움이 계속되는 중
Poisoning Attacks against Diffusion Models
diffusion 모델에 대한 공격은 제한적인 편
예를 들어 공격자가 정의한 트리거를 프롬프트에 주입하여 특정 이미지를 생성하는 backdoor attack을 제안하지만, 공격자가 denoising diffusion 단계나 모델의 전반적인 training loss를 직접 수정할 수 있다고 가정해야함
해당 논문에서는 일상적인 프롬프트에서 이미지를 올바르게 생성하는 모델의 기능을 방해하려고 함(트리거 필요X)
기존 backdoor attack과는 달리, 공격자가 train dataset에는 접근가능하지만, 모델 파이프라인에는 접근불가하다고 가정
Glaze, MIST는 데이터오염을 활용하여 모델 파인 튜닝사용하여 diffusion 기반 스타일 모방으로부터 작품 보호
이는 일반적으로 10~20개의 train dataset을 포함하는 프로세스인 로컬 모델의 파인 튜닝을 방해하고, train dataset이 보호되어있다고 가정
해당 논문은 기본 모델 자체의 일반적인 기능을 손상시키려고 하며, 소수의 poison data만 있으면 됨
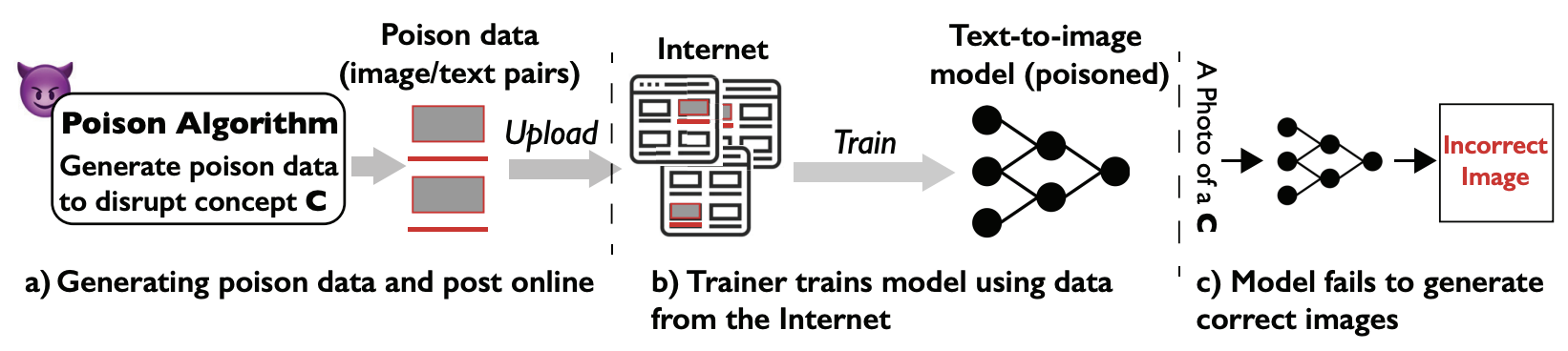
일반적인 text-to-image 생성 모델에 대한 특정 프롬프트 poison attacks의 개요 3. Feasibility of Poisoning Diffusion Models
Common Concepts as the Poison Targets
하나 이상의 특정 키워드를 대상으로 할 수 있음 ex)눈 속에서 달리는 "개", 자동차를 운전하는 큰 "개"
이런 키워드를 여기서는 concept라고 부름
3.1. Threat Model
Attacker
공격자는 일반적인 text-to-image 모델의 train data를 poisoning하여 모델이 바람직하지 않은 동작을 하도록 강제하는 것을 목표로 함
=>공격 대상이 되는 하나 이상의 개념이 프롬프트가 될 때, 잘못된 이미지를 생성하는 것
공격자의 가정
- 모델 train dataset에 poisoning data를 주입가능
- 모든 poisoning data에 대한 내용(이미지, 텍스트 둘 다)을 임의로 수정가능
- 모델 파이프라인에 접근 불가능
- 오픈 소스 text-to-image 모델에 액세스 가능
Model Training
두 가지 학습 시나리오 가정
1. 처음부터 모델을 학습
2. 사전훈련된 모델에서 시작하여 지속적으로 업데이트
3.2. Concept Sparsity Induces Vulnerability
기존 연구에 따르면 공격이 효과적이려면 train dataset의 상당 비율을 손상시켜야함
하지만 우린 아님~!~!(몇 번 얘기하는지;)
Concept Sparsity
diffusion 모델은 train dataset의 총량은 상당하지만 단일 concept와 관련된 train dataset은 제한되어 있음, 불균형한 데이터셋
ex)"개"의 경우 0.1%, "판타지"의 경우 0.04%
게다가 concept와 관련된 모든 "이웃"과 관련된 train dataset을 집계해도 희박성은 남아있음
"이웃" ex)"강아지"와 "늑대"는 모두 "개"와 관련되어있음
Vulnerability Induced by Training Sparsity
양성 concept의 이미지 생성을 손상시키려면 공격자는 깨끗한 train data와 관련 concept의 기여도를 상쇄할 만큼 충반한 poison data를 주입하면 됨
요런 clean~한 샘플의 양은 전체 train dataset에서 아주 작은 부분이므로 일반 공격자도 공격 가넝
3.3. Concept Sparsity in Today's Datasets
LAION-5B의 하위집합, 6억 개의 텍스트/이미지 쌍과 22833개의 고유한 영단어 포함
Open Multilingual WordNet을 활용하여 유효하지 않은 단어를 제거하고 모든 명사를 concept로 사용
Word Frequency
Semantic Frequency
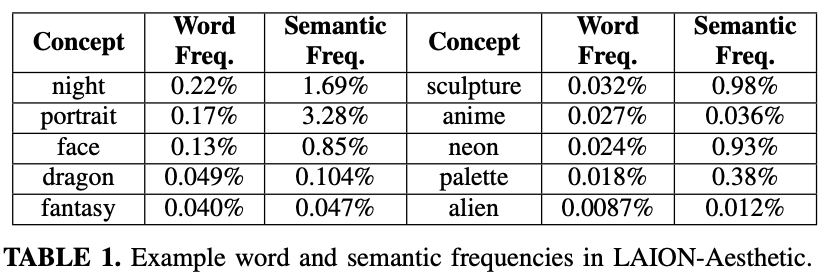
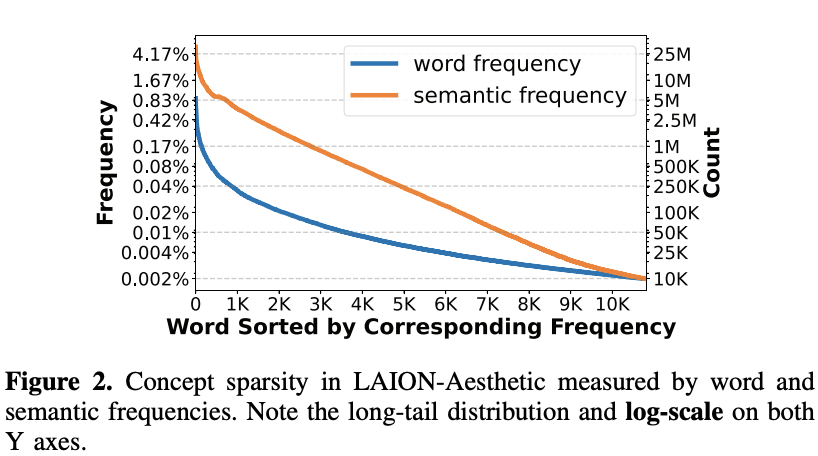
Word Frequency나 Semantic Frequency 둘 다 long tail distribution으로 구리다
4. A Simple “Dirty-Label” Poisoning Attack
poisoning attack의 다음 단계는 단순한 "dirty-label" poisoning attack의 효과를 경험적으로 검증하는 것
공격자는 텍스트/이미지 쌍을 제대로 안 줘서 모델이 특정 concept와 이미지 간 관계를 제대로 이해하지 못하도록 함

"dog"에 대해서 공격, concept "dog"을 입력해도 "cat"이 나오는 것을 볼 수 있음 시각적으로 포착은 되나, 시각적 요소는 포함되지 않는 이미지 셋과 연결시켜 교란을 줌

5. Nightshade : an Optimized Prompt-Specific Poisoning Attack
5.1. Design Goals and Potential Options
요구사항 : 더 적은 수의 poisoning sample로 성공, 인간 및 자동화된 탐지 방지
5.2. Intuitions and Optimization Techniques
5.1의 기준을 충족하기 위해 언급된 두가지 직관을 바탕으로 Nightshade설계
Maximizing Poison Potency : 성공적인 공격에 대한 poison data의 수를 줄이려면 모델 훈련에 대한 각 poison sample의 영향을 확대하는 동시에 다양한 poison sample 간 충돌을 최소화해야함
Avoiding Detection : poison data는 감지기와 인간 모두에게 자연스럽고 일관되게 나타나야 함
Maximizing Poison Potency
concept C가 프롬프트가 될 때마다 모델이 concept A를 출력하도록 하여 concept C를 공격
이를 달성하기 위해선 poison data가 C의 양성 훈련 데이터의 기여도를 넘어서야함
양성 훈련 데이터는 당연히 노이즈가 많고 최적의 상태가 아님
양성 데이터의 이러한 성질은 모델 가중치에 대한 일관되지 않은 gradient update를 생성=>올바른 concept를 학습하는 속도가 느려질 수도 있음
목표 : poison data의 분산과 불일치를 줄이는 것
1. concept C에 초점을 맞춘 프롬프트만 포함하여 poison prompt text C의 노이즈를 줄임
2. poison image A를 만들 때, poison data를 보장하기 위해 잘 정의된 concept A에서 이미지를 선택
3. 각 image A가 모델 훈련에 적합한 상태인지 확인 - "a photo of A"를 생성하기 위해 모델을 직접 쿼리하여 image A를 얻음
Avoiding Detection
A의 이미지와 text prompt C에 최적화된 poison data를 갖고 있음
(concept A의 이미지들+C라는 concept이 들어간 text prompt 이렇게 한 쌍)
하지만 텍스트-이미지 내용이 잘못 정렬되어 있기 때문에 모델 트레이너가 자동화된 정렬 분류기나 사람이 검사하는 방식을 사용하여 이런 유해한 데이터를 쉽게 발견할 수 있음=>우회하기 위해 concept C의 이미지를 image A로 대체
더보기자꾸 정렬정렬하는데 misalign이 어떤 상탠데?
깨끗한 데이터 샘플에 perturbation(인공지능에서 무슨뜻임?)을 도입하기 위해 최적화를 하고, 해당 feature representation을 다른 클래스의 깨끗한 데이터 샘플과 유사하게 변경, 이 때 사람의 검사도 피할 수 있을만큼 충분히 작게 유지됨
"guided perturbation" : concept C의 이미지와 시각적으로 동일하게 보이는 poison data 이미지를 구축
"anchor image" : 생성된 A 이미지

F는 공격자가 접근할 수 있는 text-to-image 모델의 이미지 feature extractor, D는 feature space에서의 거리함수 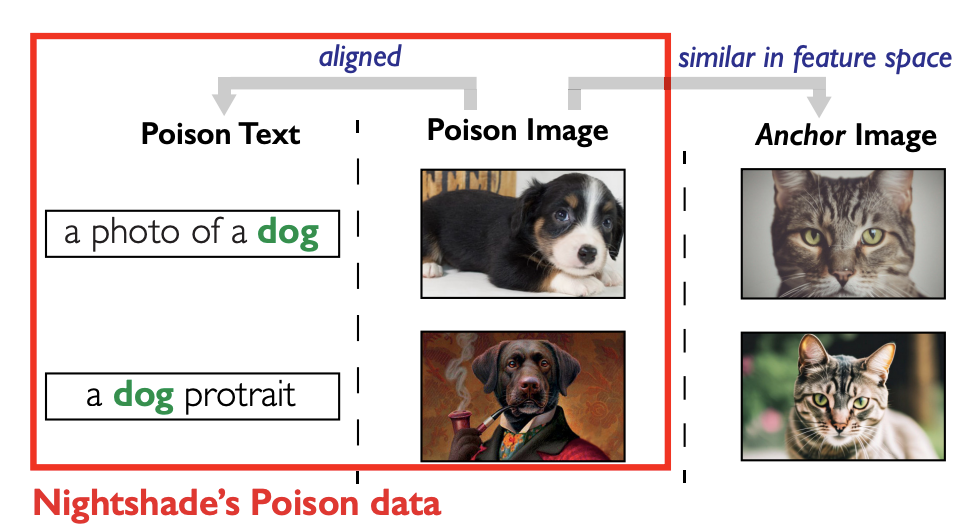
5.3. Detailed Attack Design


악필... 
진심 티 1도 안남 6. Evaluation

6.1. Experimental Setup
6.2. Attack Effectiveness
dirty-label attack에 비해 20% 줄인 poison sample들로 공격해도 잘 됨
6.3. Impact of Clean Training Data
평균적으로 concept와 관련된 clean training data의 2%에 해당하는 poison data를 주입하여 성공
6.4. Bleed-through to Other Concepts
poison이 특정 용어에만 연관되어 있을 경우엔 텍스트 프롬프트를 변경만 하면 우회가능함
하지만 우리에겐 "bleed-through"효과가 있지!
poison concept C는 관련 concept들에 영향을 미침
ex)"개"가 poison되었다고 해도 "강아지","허스키"같은 텍스트 프롬프트를 넣었을 때 생성해내는 모델의 능력도 손상시킴
워드임베딩 공간 상에서 가까울수록 영향을 줌(L2 distance사용)
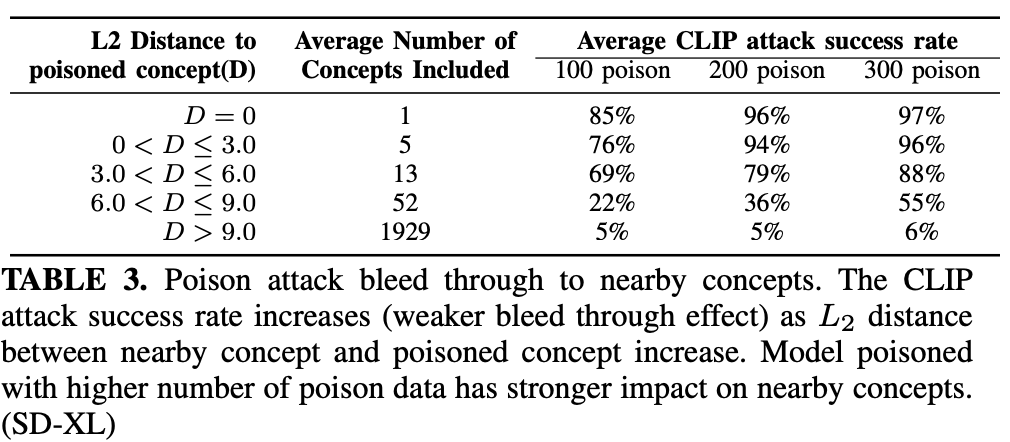

6.5. Stacking Multiple Nightshade Attacks

"fantasy art"와 관련있는 프롬프트들은 "bleed-through"효과를 받음 
요로코롬 여러 개의 프롬프트에 적용돼서 stacking되는 것도 볼 수 있움 6.6. Attack Generalizability
Nightshade는 전이작업이든 다양한 프롬프트든 뭐든간에 어디서든 짱짱이라고 한다
7. Potential Defenses
8. Poison Attacks as Copyright Protection
9. Conclusion
model trainer와 content owner가 모델에 대한 dataset의 라이센스를 협상하도록 장려하는 도구로서 잠재적인 가치를 지님
'공부 > 논문' 카테고리의 다른 글
An Image is worth 16*16 words: Transformers for image recognition at scale (0) 2024.06.06 StyleGAN 1~3 논문 리뷰 (1) 2024.03.19 VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION(VGGNet) (0) 2024.02.18 Generative Adversarial Nets(GAN) 리뷰 (2) 2024.01.11