Chapter1 딥러닝을 위한 필수 기초 수학
chapter1-1. 함수
y=f(x)=x^2
chapter1-2. 로그함수
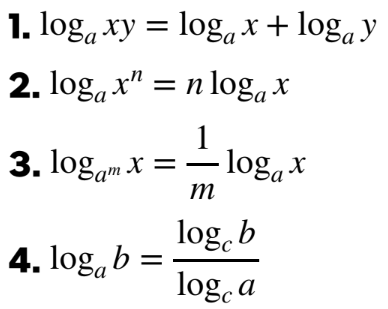
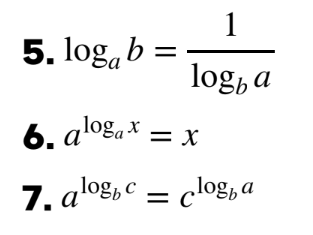
앞으로는 그냥 log라고 써져 있으면 밑이 e인 로그
chapter1-3. 벡터와 행렬

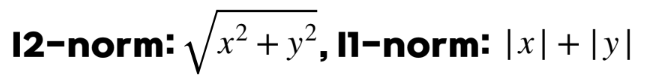
chapter1-4 전치와 내적
전치

내적




chapter1-5 극한과 입실론-델타 논법

chapter1-6 미분과 도함수
미분
=순간 변화율

도함수



chapter1-7 연쇄법칙


chapter1-8 편미분과 그라디언트
편미분

그라디언트

chapter1-9 테일러급수
Maclaurin급수
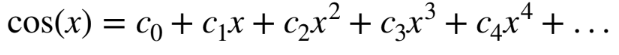
테일러 급수

chapter1-10 스칼라를 벡터로 미분하는 법



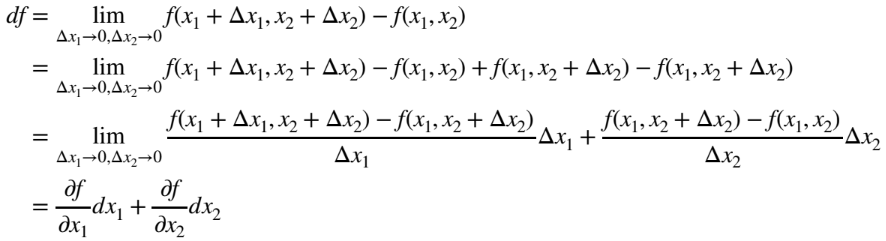



chapter1-11 왜 그라디언트는 가장 가파른 방향을 향할까




방향만 보기 위해 델타의 크기를 1로 고정한다면 L(wk+1)-L(wk)가 최대한 양수로 크려면 델타의 방향은 그라디언트 방향과 일치해야함
=>델타만큼 업데이트할 때 그라디어트 방향으로 업데이트하는게 가장 L을 키울수 있는 방향
chapter1-12 벡터를 벡터로 미분
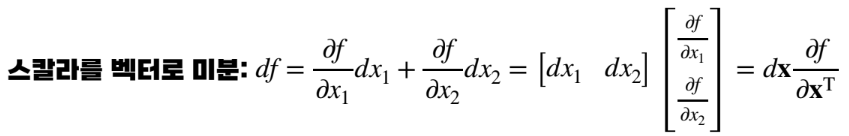


chapter1-13 벡터를 벡터로 미분할 때의 연쇄법칙




chapter1-14 스칼라를 행렬로 미분하는 방법
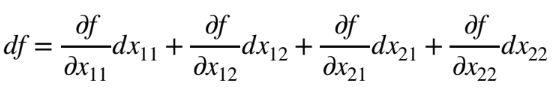



chapter1-15 행렬을 행렬로, 벡터를 행렬로 미분하는 법






chapter1-16 랜덤 변수와 확률 분포
평균
종류 : 1. 산술평균 2.기하평균 3.조화평균
수업에서 다룰 평균은 기댓값(Expectation)
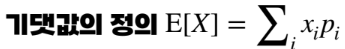

분산
평균으로부터 얼마나 퍼져있는지 정도를 알려주는 값


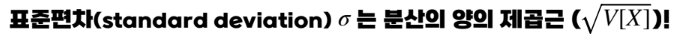
chapter1-17 균등 분포와 정규 분포
균등 분포

정규 분포

chapter1-19 최대우도추정(MLE)
개쩐다,,,나 이거 이해 여태 못했는데 한방에 함
ex)P(카톡빈도|그녀의 마음)->카톡빈도로 그녀의 마음을 알아내기
만약 카톡빈도가 5시간정도라면 그녀의 마음은 나에게 없을 가능성이 큼->이걸 알아내는 게 최대우도추정
즉 P(x|b)이면 b의 값이 최대가 되려면 x가 무슨값이 되어야할까?

chapter1-20 최대 사후 확률
likelihood뿐만 아니라 prior distribution까지 고려한 posterior를 maximiaze하는 것



MLE와 비교하면 p(x)가 추가된 것을 알 수 있고 p(x)를 안다는 것은 x의 분포를 사전에 알고있다는 의미
->사전 정보를 제공해주는 것이므로 prior distribution이라고 함

Chapter 1- 21 정보 이론 기초





본 게시글은 패스트캠퍼스 [혁펜하임의 AI DEEP DIVE] 체험단 활동을 위해 작성되었습니다.